Lab 3 - User-space thread library
Class: CSCE-313
Notes:
Instructions
This lab may seem a little difficultT1, so please start early. Once you get the hang of context switching, you'll be in a good position to understand how other languages use user-space threads to simplify concurrent programming. C++ does not have a user-space thread implementation in the standard library.
See for example, goroutines in GoLangT2 and green threads in Java 1.0 if you are interested. There are lots of subtle issues in implementing user-space threads. For one, because user-space threads are invisible to the OS kernelT3, if any user-space thread makes a system call, it can potentially block the entire process. This can drastically affect program latency. Also, if user-space threads are purely cooperative, then it's possible for one thread to never yield the CPU and starve all other threads. Real implementations such as goroutines handle these issues.
1. Introduction
The objective of this lab is to implement a simple user-space, cooperative, multi-tasking thread library. Let's take a look at what each of these words mean one by one.
-
User-space means that this library will be linked against user programs—such as the programs you write, editors, web browsers, etc., and the code in the library will be executed as part of your program. It means that we won't need any modifications in the kernel.
-
Cooperative means that the workers—i.e., the independent units of execution in your program, cooperatively yield control to other workers. This is different from how operating systems are usually implemented. Typically, the OS preempts a worker thereby taking control from it, rather than relying on the worker to willingly yield the control. The reason that OSes typically do this (known as preemptive multitasking) is to be fair in CPU allocation to all the workers—both within a process and globally. The workers may be faulty or malicious and never yield the CPU to another worker.
Preemptive multitasking, however, comes at a cost of higher complexity because the OS is typically unaware of the optimal time-slice for a worker. To avoid complexity in implementation, we've chosen a cooperative design in which workers explicitly yield control. You can read more about these two design choices on StackOverflow.
-
Multi-tasking is a catch-all term for multi-threading and multi-processing. Strictly speaking, in this lab we won't create threads that are independently schedulable entities; rather what we'll create are tasks. A task is defined as a unit of work which the parallel runtime (the OS, or a parallel runtime user-space library like the one in this assignment) guarantees will get completed. A parallel runtime is defined as the set of function calls and their behavior which allows program code to be parallelized.
In some user-space parallel runtimes, tasks share the same stack. However, in this library which you'll implement, each worker explicitly allocates the stack for its use.
Because machine registers are shared between the various tasks (because the library executes on the same processor), we need to save the state of the machine, also called the context, whenever we switch to a different task. These contexts, which include the values of various architectural registers, are stored in a specific data structure in the library. Therefore, whenever we want to switch the control over to a new task we need to perform two steps: (1) save the current context, and (2) switch over to the new context stored in the internal data structure. Moreover, since the context holds the complete information of the state of the machine when the context was captured, when we resume from a context it appears as if we went back in time and started from where we had left off, i.e. from the point of context capture.
In this lab, you are not expected to write various functions which deal with saving and restoring the snapshots, rather you only need to deal with resuming the correct context at the correct time. We'll use the ucontext.h header provided by the standard C library, i.e. libc, which is available on UNIX systems for this lab. More details on the header can be found in the man pages. Please refer to the man page for makecontext for an example program. You can use whatever libc calls and syscalls that you want for this lab. However, please note that this lab can be completed using only three function calls declared in ucontext.h: swapcontext, getcontext, and makecontext. The TAs will cover the semantic of all these three functions in the lab sessions to get you started.
Since many of you might not have used these functions before, and many of you might not have written a parallel runtime before, we recommend you to get started as early as possible since this lab will take some time.
2. The Library Calls
The ucontext.h headers and its functions operate on objects of the type ucontext_t. More details of this type can be found in the man pages for getcontext. This structure represents a captured context of the machine.
-
getcontext(ucontext_t *ucp): This function takes a pointer to an object of the typeucontext_tand populates the various field of the object such that after the call togetcontext, it contains a valid captured context of the machine. Note that this context can then be used to restore the machine state to the point where the context was captured, i.e. to the point just after the call togetcontext.- You can think of this “state” as comprising of the processor state (registers) + some process-specific state such as the process's signal mask. When the saved state is activated, it appears as if
getcontext()returned again. - Note that there's only one process that is multiplexing different threads of control, so all the “threads” inherit the same signal mask.
- You can think of this “state” as comprising of the processor state (registers) + some process-specific state such as the process's signal mask. When the saved state is activated, it appears as if
-
makecontext(ucontext_t *, (void (*)()) func, <nargs>, arg1,...): This function takes a pointer to an object of the typeucontext_tand modifies it. The object which is passed to this function must be a valid context.This function also takes in a function pointer, the number of arguments to be passed to the function, and all the arguments which are to be passed to the function. This function modifies the context which was passed to it (via the pointer) such that whenever this context is resumed, the control jumps to the first instruction of the function whose function pointer was passed. The function which was passed gets called with the arguments specified in the call to
makecontext.However, note that although this call modifies the context such that it executes the right function when it is resumed, it does not set up the stack for the call to this function. This task is left to the users of the
makecontext, which happens to be you in this case.- To setup the stack you need to set the pointer
context.uc_stack.ss_spto some space in memory which can be used for the stack (you can simplymallocsome space for this). - You need to set
context.uc_stack.ss_sizeto the size of the stack space which you've allocated. - You need to set
context.uc_stack.ss_flagsto 0 because the child task is not required to handle any signals. - Finally, you need to set
context.uc_linktoNULLto indicate that once the function finishes execution, the worker can simply terminate. You can optionally make this field point to anotherucontext_tobject which would be resumed after the specified function exits. Setting this field toNULLensures that the worker would exit after executing the specified function.
Once you've used the
makecontextcall and completed the four tasks listed above, the context which you modified is finally ready to be used.getcontext(ucp); ucp->uc_stack.ss_sp = (char *) malloc(STACK_SZ); ucp->uc_stack.ss_size = STACK_SZ; ucp->uc_stack.ss_flags = 0; ucp->uc_link = NULL; makecontext(ucp, (void (*)()) fn, 2, arg1, arg2);You can find the sources for
makecontextinglibcundersysdeps/unix/sysv/linux/x86_64/makecontext.c. It basically saves the function address in%rip, the function arguments in%rdi,%rsi, etc., saves the stack pointer in%rspso that when this context is restored, the function starts executing with the correct arguments.You can think of this function informally as building a stack frame on the stack referenced in
ucontext_t. This is very convenient because it allows us to construct the initial stack frame for a new thread. Note that the way a function is called is dependent on the function calling convention of the processor architecture.In x86-64, arguments are mostly passed through registers. A new thread can therefore be created by specifying the function that the thread should start executing in, along with its arguments. The
glibcimplementation ofmakecontextexpects only integer arguments to function and nargs is the # of arguments to function.If you set
context.uc_link = NULL, and the function you specified inmakecontext()returns (i.e., reaches the end of the function), then the process terminates by callingexit(0). That is, control doesn’t return to the calling context or thread—instead, the process exits cleanly as ifexit(0)was called. This is specified in POSIX and observed in implementations likeglibc.We clearly don't want that so we'll add the requirement that any thread must call
t_finishbefore exiting the function. We can avoid this requirement by making amakecontextwith a new function such ast_terminatewhich in turn calls the required function. That way, when the function returns,t_terminatecan callt_finish. But we want to keep this lab simple. - To setup the stack you need to set the pointer
-
swapcontext(ucontext_t *from, ucontext_t *to): This function takes two pointers to two distinct contexts as its arguments. It then saves the current context, i.e. the context of the caller, in the first argument and restores the execution from the second context. Note that when the execution is restored, the control would jump to wherever the second context was created. This means that if the call toswapcontextdoesn't fail, then the control is not guaranteed to return to the call site.
3. API Details
The API of the library that you need to implement is listed in the README.md file in the starter code. The function signatures of various calls which you need to provide are mentioned in threading.h. The TAs will also go over the function signatures in the labs.
void t_init(): This is the first function which is called by any program that uses the library. You can use this function to initialize various data structures which your library may or may not be using.int32_t t_create(fptr foo, int32_t arg1, int32_t arg2): This call is used to create a task represented by the functionfoowith two arguments,arg1andarg2. Note that thefptrtype is a function pointer of the typevoid (*fptr)(int32_t, int32_t)i.e.foomust be a pointer to a function which returns nothing, i.e.void, and which must take two 32-bit signed integer argumentsarg1andarg2. For an example of such a function and the usage oft_create, seemain.c.t_yield(): This function is called by a worker to indicate that it can relinquish the control over to other workers at the call site oft_yield. The existence of this function tells us that this library is a cooperative multi-tasking library.t_finish(): This function is called by all workers, except the main worker which spawns all the tasks, at the very end to indicate the completion of the assigned task.
Please refer to threading.h for more details about the exact API that you need to implement.
#include <stdint.h>
#include <stdlib.h>
#include <string.h>
#include <ucontext.h>
#ifndef COOPERATIVE_MULTITASKING
#define COOPERATIVE_MULTITASKING
#define STK_SZ 4096
#define NUM_CTX 16
enum context_state {
INVALID = 0, // The context entry is invalid
VALID = 1, // The context entry is valid and ready to be used
DONE = 2, // This context has completed its work
};
struct worker_context {
enum context_state state;
ucontext_t context;
};
extern struct worker_context contexts[NUM_CTX];
extern uint8_t current_context_idx;
typedef void (*fptr) (int32_t, int32_t);
typedef void (*ctx_ptr) (void);
void t_init ();
int32_t t_create (fptr foo, int32_t arg1, int32_t arg2);
int32_t t_yield ();
void t_finish ();
#endif
4. The Starter Code
The stater code comes with seven files as described below.
Problem.pdf: This document which describes the task for Lab 3.main.c: The code which uses the library that you'll implement. You are not allowed to modify this file as this is the test application which we'll use to evaluate your submission. However, if you want to write other programs which use your implementation for testing purposes, you can always copy this file somewhere else and then make changes to it.Makefile: The Makefile to build the library and the executable. You can modify this file if you so desire, but you probably won't have to.README.md: This file provides more details about the task.threading.c: This file holds the implementation of the library. You are expected to modify this file however you want. To get you started, we've provided sections in this file where you can write your code. These sections are marked withTODOs.threading_data.c: This file defines all the variables which your library implementation may or may not use. You can modify this file if you want, but you probably won't have to. However, note that if you add/remove various variables to/from this file, make sure to add the correspondingexterndeclarations for them inthreading.h.threading.h: This is the header file for the library which is used bymain.c. This file has all the information about the various calls that you've to implement. You can only add declarations in this file but you are not allowed to remove any of the function declarations. If you do remove any of these declarations, then the code would fail to compile.
The starter code is structured as a dynamically linked (it's linked at runtime) shared library. The code that you'll write in threading.c will be used to compile a shared library named libthreading.so. This library can then we used with any other program.
main.c implements one such program that uses the library. To use the functions supported by the library, main.c includes threading.h. When main.c is compiled to generate the executable main, it is linked with the shared library.
As a result, whenever main calls one of the library functions, the function is invoked in the libthreading.so shared library. The Makefile handles all of the compilation logic. The output of the Makefile is one executable, main, and one dynamically linked shared library, libthreading.so.
5. Hints
5.1 An illustrative example
Consider the example code shown. When this code is compiled and run with an argument, here's what happens when argc > 1.
main prints main: swapcontext(&uctx_main, &uctx_func2) and swaps to uctx_func2. (This
starts func2. func2 runs.)
prints func2: started
prints func2: swapcontext(&uctx_func2, &uctx_func1)
swapcontext(&uctx_func2, &uctx_func1) transfers to func1.
func1 runs
prints func1: started
prints func1: swapcontext(&uctx_func1, &uctx_func2)
swapcontext(&uctx_func1, &uctx_func2) transfers back to func2.
Back in func2 after its swapcontext returns
prints func2: returning
func2 returns. (Because uc_link is NULL (argc > 1), there is no successor context.
Returning from a ucontext with uc_link == NULL terminates the thread/process via
setcontext semantics; the program ends here. Control does not go to main, and
func1’s “returning” line is never printed.)
When the program is run without arguments, its output is the following.
main: swapcontext(&uctx_main, &uctx_func2)
func2: started
func2: swapcontext(&uctx_func2, &uctx_func1)
func1: started
func1: swapcontext(&uctx_func1, &uctx_func2)
func2: returning
func1: returning
main: exiting
Key points:
- With no argument, returning from
func2goes tofunc1(viauc_link). - Returning from
func1goes tomain(viauc_link). mainthen continues and exits normally.
An example of the ucontext API
#include <stdio.h>
#include <stdlib.h>
#include <ucontext.h>
static ucontext_t uctx_main, uctx_func1, uctx_func2;
static void func1 (void) {
printf ("%s: started\n", __func__);
printf ("%s: swapcontext(&uctx_func1, &uctx_func2)\n", __func__);
swapcontext (&uctx_func1, &uctx_func2);
printf ("%s: returning\n", __func__);
}
static void func2 (void) {
printf ("%s: started\n", __func__);
printf ("%s: swapcontext(&uctx_func2, &uctx_func1)\n", __func__);
swapcontext (&uctx_func2, &uctx_func1);
printf ("%s: returning\n", __func__);
}
int main (int argc, char *argv[]) {
char func1_stack[16384];
char func2_stack[16384];
getcontext (&uctx_func1);
uctx_func1.uc_stack.ss_sp = func1_stack;
uctx_func1.uc_stack.ss_size = sizeof (func1_stack);
uctx_func1.uc_link = &uctx_main;
makecontext (&uctx_func1, func1, 0);
getcontext (&uctx_func2);
uctx_func2.uc_stack.ss_sp = func2_stack;
uctx_func2.uc_stack.ss_size = sizeof (func2_stack);
/* Successor context is f1(), unless argc > 1 */
uctx_func2.uc_link = (argc > 1) ? NULL : &uctx_func1;
makecontext (&uctx_func2, func2, 0);
printf ("%s: swapcontext(&uctx_main, &uctx_func2)\n", __func__);
swapcontext (&uctx_main, &uctx_func2);
printf ("%s: exiting\n", __func__);
exit (EXIT_SUCCESS);
}
5.2 Experiment with libthreading.a
Download libthreading.a and compile it with main.c as follows:
gcc main.c libthreading.a -o main
./main
You can change the program in main.c to experiment with our threading library. The library is not vey robust so don't try anything fancy. But you should get a good feel for context switching. Send me your questions and I'll answer them during lecture.
5.3 Code organization
Please note that the hints provided here are merely suggestions. You are under no obligation to follow them. You can use the contexts array defined in threading_data.c to store all the contexts. You can also use current_context_idx to keep track of which context is active right now. You may assume that:
- All worker threads are started before the main thread calls
t_yield(). - The context of the main thread is in a fixed index in the proc table, say 0. This naturally results in the outcome that when all worker threads finish, control returns to the main thread.
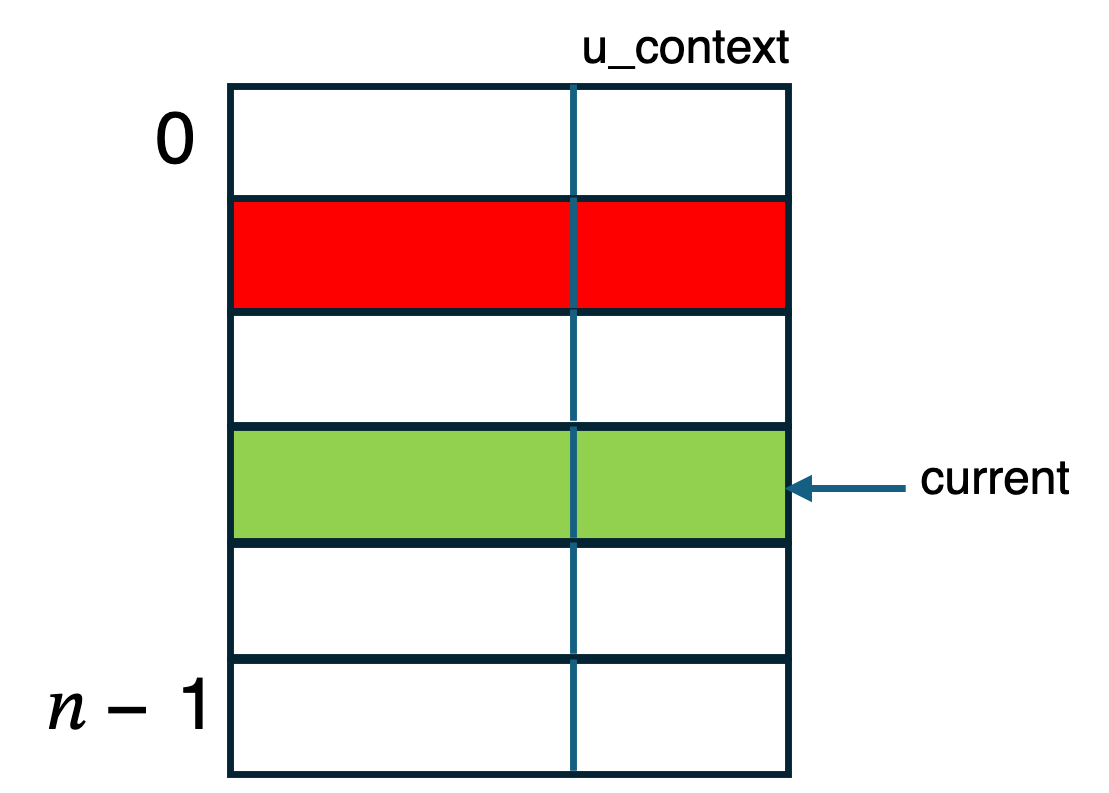
Here's a diagram of the proctable that contains an entry for each worker thread. Slots in the table correspond to worker threads and a slot contains a ucontext_t that saves the context of the thread.
-
t_init(): You can use this function to initialize various data structures that your library uses such ascontextsandcurrent_context_idx. -
t_create(): In this function you can first find an empty entry in thecontextsarray. You can use thestatefield of thestruct worker_contextandenum context_stateto track which entries are unused, i.e.INVALID. Then you can initialize this entry usinggetcontext. After initializing the entry you can then usemakecontextto modify the context such that it calls the function passed as the argument tot_create(). Make sure to also allocate the stack for the context here. You may also optionally choose to schedule the new context at this point itself.int32_t t_create(fptr foo, int32_t arg1, int32_t arg2) { // the caller uses the current slot in the proc table next = find_next_free(); if(next == curr) return ERROR; // no free slots use makecontext to create a frame for foo(arg1, arg2) return SUCCESS; } -
t_yield(): In this function you can first update the current context (whose index is stored incurrent_context_idx) by taking a fresh snapshot usinggetcontext. Then you can search for a VALID context entry in thecontextsarray and useswapcontextto switch to it. After this you can then compute the number of contexts in the VALID state and return the count. Note that since the switch happens before you compute the number of contexts in the VALID state, when the original context is resumed, the calculation of this count will be done at that point.int t_yield() { // the caller uses the current slot in the proc table next = find_next_valid(); if(next == curr) return ERROR; // only caller remains atomically: save caller's context in current; restore context from next; return SUCCESS; } -
t_finish(): In this function you can first free the stack allocated for the current context. Then you can reset the context entry to all zeros by usingmemset.void t_finish() { free the entry in slot current; // there's at least one for the main thread next = find_next_valid(); use setcontext to set context with proctable[next] }
Testing
Note that since the Address Sanitizer is not fully complaint with the ucontext.h library, we'll use another tool called valgrind to check for leaks. To use this tool, you need to install it on your machine by running sudo apt-get install valgrind. However, note that valgrind does not play nice with ucontext.h by default. Therefore, we'll only use it to detect memory leaks and we'll ignore all the other errors that it reports.
To run valgrind you can execute
valgrind --leak-check=full --show-leak-kinds=all --track-origins=yes ./main
after building the code. If your code is free of any memory leaks, you should see
All heap blocks were freed -- no leaks are possible
Implementation
t_init()
1) Mark every slot as unused
contexts is an array of struct worker_context, and each entry has a state. Unused entries should start as INVALID.
Why?
- t_create() will later search for an INVALID slot to place a new task.
- If you don’t initialize these states, you could treat garbage memory as “VALID,” and your scheduler (t_yield) would try to run junk contexts.
So: loop i = 0..NUM_CTX-1 and set contexts[i].state = INVALID.
2) Choose which context is currently running
At the moment t_init() runs, the currently executing code is the main program thread (the one that will create tasks and later call t_yield()).
So you should set:
current_context_idx = 0;
This means: "slot 0 represents whoever is running right now (main)."
This matches the lab hint: main context is at a fixed index "say 0."
3) Save the “main” context into slot 0
This is the key conceptual step.
When you later swapcontext(&contexts[main].context, &contexts[worker].context), the “from” context must contain a valid snapshot of the main thread’s registers/stack pointer/instruction pointer, so that when the worker yields back, execution resumes exactly after the swapcontext call.
That’s what getcontext() gives you: it captures the current execution state into a ucontext_t. The lab describes context capture and how resuming looks like “going back in time” to where you left off.
So in t_init():
- call
getcontext(&contexts[0].context); - mark
contexts[0].state = VALID;
Note: For main, you typically do not allocate a new stack in t_init(). The main thread is already running on a real process stack, and getcontext() captures that.
A clean implementation
#include <threading.h>
void t_init()
{
// 1) Start with a clean proc table: mark all slots unused (INVALID)
for (int i = 0; i < NUM_CTX; i++) {
contexts[i].state = INVALID;
}
// 2) The main thread is treated as context slot 0
current_context_idx = 0;
// 3) Capture the current (main) execution context into slot 0
// so we can later return to it via swapcontext/setcontext.
getcontext(&contexts[0].context);
// 4) Mark main context as ready/VALID
contexts[0].state = VALID;
}
What's "going on" when getcontext() runs?
Think of it like taking a snapshot of:
- the CPU registers,
- the current stack pointer,
- and where execution should continue.
Later, when something does setcontext(&contexts[0].context) or swapcontext(..., &contexts[0].context), the CPU restores that snapshot and continues as if it never left (typically resuming right after the corresponding swapcontext call that saved it).
t_create(foo, arg1, arg2)
Mental model: what is t_create building?
A ucontext_t is basically a saved CPU/stack snapshot plus enough info for the OS/libc to restore it later.
For a new “thread” that hasn’t run yet, you need to construct its initial execution state so that:
- it has its own stack memory (so it doesn’t overwrite main’s stack),
- its instruction pointer is set so that when restored, it begins at foo,
- and registers/ABI state are set so that foo receives arg1 and arg2.
That's what makecontext() does: it modifies the ucontext_t so that “when resumed, start by calling this function with these integer args.”
0) Find a free slot in contexts[]
You need a slot whose state == INVALID.
- Slot 0 is usually main (from
t_init), so you typically start searching from 1. - If you can’t find any free slot, return 1 (failure), as required by the API comment in
threading.h.
1) Initialize the context object with getcontext
You must call getcontext(&contexts[idx].context) first.
Why?
- It fills in required internal fields in
ucontext_t. makecontext()expects a “valid context object” to modify.
2) Allocate a stack and attach it to the context
A newly created task can’t use main’s stack. You give it its own stack:
void *stack = malloc(STK_SZ);
Then set:
uc_stack.ss_sp = stack;uc_stack.ss_size = STK_SZ;uc_stack.ss_flags = 0;
3) Decide uc_link
The lab’s “how to setup stack” section says to set uc_link = NULL and explains that it means if the function returns, the process exits. 
Then it immediately says: we don’t want that, so they require that any thread must call t_finish before exiting (i.e., foo must call t_finish at the end). 
So in this lab’s design, it’s acceptable to do:
contexts[idx].context.uc_link = NULL;
...but you must remember: if a worker forgets to call t_finish() and just returns, your whole program can exit.
4) Use makecontext so the task starts at foo(arg1,arg2)
This is the line that “programs” the new context:
makecontext(&contexts[idx].context, (ctx_ptr)foo, 2, arg1, arg2);
Notes:
makecontextwants a function pointer of typevoid (*)()(no declared args), so you cast. The lab shows(void (*)()) fnin its example.- In
threading.hthere is actually a type declaration for this:typedef void (*ctx_ptr)(void);
- In
- You pass 2 because there are two args.
- On x86-64 glibc, those integer args are set up so the function sees them normally.
5) Mark the slot as runnable
Finally set:
contexts[idx].state = VALID;
Return 0 for success.
A solid t_create() implementation
int32_t t_create(fptr foo, int32_t arg1, int32_t arg2)
{
// 0) Find an unused slot (INVALID) in the context table.
// Typically slot 0 is reserved for main.
int next = -1;
for (int i = 1; i < NUM_CTX; i++) {
if (contexts[i].state == INVALID) {
next = i;
break;
}
}
if (next == -1) {
// No free slot available
return 1;
}
// 1) Initialize the ucontext_t structure in that slot.
// makecontext requires a valid context to modify.
if (getcontext(&contexts[next].context) == -1) {
return 1;
}
// 2) Allocate a private stack for this new context.
void *stack = malloc(STK_SZ);
if (stack == NULL) {
return 1;
}
contexts[next].context.uc_stack.ss_sp = stack;
contexts[next].context.uc_stack.ss_size = STK_SZ;
contexts[next].context.uc_stack.ss_flags = 0;
// 3) If foo ever returns and uc_link == NULL, the process may exit.
// Lab requires workers call t_finish() instead of returning.
contexts[next].context.uc_link = NULL;
// 4) Modify the context so that when it is first scheduled,
// it begins execution at foo(arg1, arg2).
makecontext(&contexts[next].context, (ctx_ptr)foo, 2, arg1, arg2);
// 5) Mark this slot runnable.
contexts[next].state = VALID;
return 0;
}
t_yield()
t_yield() is the “scheduler” of your cooperative threading library: the current running task voluntarily gives up the CPU, and you switch into another VALID context using swapcontext. The lab’s hint is basically:
- find another VALID context (find_next_valid)
- if none exists besides the caller, return an error
- otherwise “atomically” save current + restore next (that’s exactly what swapcontext does)
Also, your header says the return value should be:
- # of VALID contexts other than the caller if successful
- -1 if not successful
And the lab notes an important subtlety: since the switch happens before you compute the count, that count is computed when the original context is later resumed.
What’s happening conceptually when you “yield”
Assume current_context_idx = curr.
-
Pick who to run next
- Scan
contexts[]to find some other slotnext != currwherestate == VALID. - Typically you scan circularly (curr+1, curr+2, ... wrap around) so scheduling is fair-ish.
- Scan
-
If nobody else is runnable, fail
- If the only VALID context is the caller, there’s nothing to yield to → return -1. (Matches the lab pseudocode:
if(next == curr) return ERROR;)
- If the only VALID context is the caller, there’s nothing to yield to → return -1. (Matches the lab pseudocode:
-
Switch contexts using swapcontext
swapcontext(&contexts[curr].context, &contexts[next].context)does two things:- Saves the current CPU/register/stack state into
contexts[curr].context - Restores the saved state from
contexts[next].contextand jumps into it
- Saves the current CPU/register/stack state into
- This means
swapcontextmight not “return” right away. It returns only when some future yield (or finish) switches back intocurr.
-
When you resume later, compute the return value
- After you’re scheduled back into
curr, execution continues right after theswapcontextcall. - Now count how many contexts are VALID excluding the caller and return that number. This matches the lab’s note about counting after the switch.
- After you’re scheduled back into
Implementation guide (with code)
#include <threading.h>
int32_t t_yield()
{
int curr = current_context_idx;
// 1) Find the next VALID context (circular scan), excluding curr.
int next = curr;
for (int step = 1; step < NUM_CTX; step++) {
int i = (curr + step) % NUM_CTX;
if (contexts[i].state == VALID) {
next = i;
break;
}
}
// 2) If next == curr, no other VALID contexts exist → error.
if (next == curr) {
return -1;
}
// 3) Switch to the next context.
// swapcontext saves curr into contexts[curr].context and resumes next.
current_context_idx = (uint8_t)next;
swapcontext(&contexts[curr].context, &contexts[next].context);
// 4) IMPORTANT: We only reach here when 'curr' gets scheduled again later.
// Now compute how many OTHER contexts are still VALID.
int32_t count = 0;
int me = current_context_idx; // after resuming, this should be "curr"
for (int i = 0; i < NUM_CTX; i++) {
if (i != me && contexts[i].state == VALID) {
count++;
}
}
return count;
}
Why I didn’t call getcontext() here
- The lab text says you “can” take a fresh snapshot with
getcontext, butswapcontextalready saves the caller’s context into the from argument as part of its definition.  - So calling
getcontext()first is usually redundant. The pseudocode block in the lab also frames the “atomic save+restore” as one step, which is exactlyswapcontext. 
Common gotchas (so you can debug faster)
- Forgetting to update current_context_idx before switching: then the library “thinks” the wrong thread is running.
- Returning the count before switching: you’ll compute in the wrong task; the lab warns about this ordering. 
- Excluding the caller in the count: the header explicitly says “apart from the caller.”
t_finish()
t_finish() is the “I’m done, delete me, and never schedule me again” call.
The lab’s hint for t_finish() is very direct:
- free the stack allocated for the current context
- memset the context table entry to zero
- find a next VALID context (there’s at least main)
- use setcontext to jump into it
The key difference vs t_yield() is: t_finish() should not come back to the finished thread. So you typically use setcontext() (one-way jump) rather than swapcontext() (save+return later).
1) Identify "who am I?"
- The current running task is tracked by:
current_context_idx
- So:
curr = current_context_idx;
This is the slot you’re about to destroy.
2) Free this thread's stack
In t_create() you did:
malloc(STK_SZ)- stored that pointer in
contexts[idx].context.uc_stack.ss_sp
So when the task is done, you must free it, or valgrind will report leaks (the lab even points you to valgrind for this). 
So:
free(contexts[curr].context.uc_stack.ss_sp);
Important note: You should only free stacks that were actually allocated.
- In this lab design,
t_finish()is called by worker tasks (not main), so it’s normally safe. - As a defensive habit, you can check
ss_sp != NULLbefore freeing.
3) Clear the proc-table slot
The lab says: “reset the context entry to all zeros by using memset.” 
This does two helpful things:
- clears the
ucontext_tfields (no stale pointers) - sets state back to 0, which matches INVALID in your enum (INVALID = 0)
So:
memset(&contexts[curr], 0, sizeof(struct worker_context));
After this, the slot becomes reusable by future t_create() calls (even though the lab assumes all workers are created before yielding, it’s still correct)
4) Pick the next runnable context
Now you need to schedule someone else. The hint says:
- “there’s at least one for the main thread”
- next = find_next_valid()
So you do the same style of circular scan you used in t_yield(), but now starting from the slot after curr.
5) Jump to that context using setcontext
setcontext(&contexts[next].context) restores that context and does not return if successful.
This is exactly what we want: the finished thread never runs again.
(If setcontext fails, that’s basically a fatal error in this tiny lab library.)
Implementation
#include <threading.h>
void t_finish()
{
int curr = current_context_idx;
// 1) Free the stack for this worker (allocated in t_create).
// (Defensive: only free if non-NULL.)
void *stk = contexts[curr].context.uc_stack.ss_sp;
if (stk != NULL) {
free(stk);
}
// 2) Clear out this proc-table entry (also makes state == INVALID because INVALID == 0).
memset(&contexts[curr], 0, sizeof(struct worker_context));
// 3) Find the next VALID context to run (there should be at least main at index 0).
int next = -1;
for (int step = 1; step < NUM_CTX; step++) {
int i = (curr + step) % NUM_CTX;
if (contexts[i].state == VALID) {
next = i;
break;
}
}
// 4) Switch to it permanently.
// If next is still -1, something is badly wrong (no runnable contexts).
if (next >= 0) {
current_context_idx = (uint8_t)next;
setcontext(&contexts[next].context);
}
// If setcontext succeeds, we never reach here.
// If we do reach here, treat it as a hard failure (or just return).
}
Why setcontext instead of swapcontext here?
swapcontext(from,to)would save the current (soon-to-be-dead) thread into from, meaning it could theoretically be resumed later.t_finish()is explicitly: "delete me and never schedule me again" (your header says this, and the lab hint matches it). 
So setcontext is the clean "one-way jump."
Common Errors
‘i’ might be clobbered
threading.c: In function ‘t_create’:
threading.c:21:9: error: variable ‘next’ might be clobbered by ‘longjmp’ or ‘vfork’ [-Werror=clobbered]
21 | int next = -1;
| ^~~~
threading.c:22:14: error: variable ‘i’ might be clobbered by ‘longjmp’ or ‘vfork’ [-Werror=clobbered]
22 | for (int i = 0; i < NUM_CTX; i++) {
| ^
cc1: all warnings being treated as errors
make: *** [Makefile:21: libthreading.so] Error 1
- Those errors are a classic side-effect of
ucontextbeing implemented usingsetjmp/longjmp-like machinery. GCC warns that non-volatile local variables may not have the value you expect after a context switch, because restoring a context is similar to a non-local jump. - Since your build uses
-Werror, that warning becomes a hard error.
Why it’s happening
- In
t_create()you callgetcontext()(directly or indirectly) and GCC conservatively assumes that the function could return in a “weird” way (likelongjmp). It then warns that locals likenextandi“might be clobbered”. - Even if you know
t_create()doesn’t context-switch, the compiler can’t always prove it whenucontextis involved.
Fix A: avoid keeping those variables "alive" across getcontext()
-
Restructure the function so that variables used before
getcontext()are not needed after, or store them in something that isn’t a normal local that GCC worries about. -
A simple pattern:
- Find the slot first
- Store it into a global-ish stable place (or recompute)
- Then call
getcontext()
For example:
int32_t t_create(fptr foo, int32_t arg1, int32_t arg2)
{
int idx = -1;
// Find free slot (start at 1 if 0 is main)
for (int k = 1; k < NUM_CTX; k++) {
if (contexts[k].state == INVALID) {
idx = k;
break;
}
}
if (idx == -1) return 1;
// From here on, avoid loop variables that live across getcontext
if (getcontext(&contexts[idx].context) == -1) {
return 1;
}
void *stack = malloc(STK_SZ);
if (!stack) return 1;
contexts[idx].context.uc_stack.ss_sp = stack;
contexts[idx].context.uc_stack.ss_size = STK_SZ;
contexts[idx].context.uc_stack.ss_flags = 0;
contexts[idx].context.uc_link = NULL;
makecontext(&contexts[idx].context, (ctx_ptr)foo, 2, arg1, arg2);
contexts[idx].state = VALID;
return 0;
}
- This often eliminates the warning because k is scoped to the loop and not “live” across getcontext().
Fix B: mark the locals as volatile
This is the direct fix for “might be clobbered” warnings:
volatile int next = -1;
and similarly for any variable the warning complains about.