06 - Multi-Layer Perceptron-Networks
"Now we are talking about something that is not linear"
XOR: A Limitation of the Linear Model
- Linear model: just 2 layers: input layer and output layer
- One way to make this model not linear is to make it wider (still 2 layers)
- This is called kernel methods
- How to make it wider? you make the input vector to be larger?
- Usually we do not count the softmax layer
- The way to make it wider is to apply
- Now
is a wider vector - This model will be not linear in terms of
- Now
- How do we do transformations to a vector
? - We apply
transformations is a vector that makes the components be multiplied by some other components. - You end up increasing the dimension of
- We apply
- In training, you only need this: $$\phi^T(x_i)\phi(x_j) = (x_i^Tx_j)$$
- The pairwise inner product with
- The pairwise inner product with
- There is a more efficient way to do this, which is deep learning (making a model to be deep)
- Kernel methods = use pairwise inner product
- Can be computed very efficient
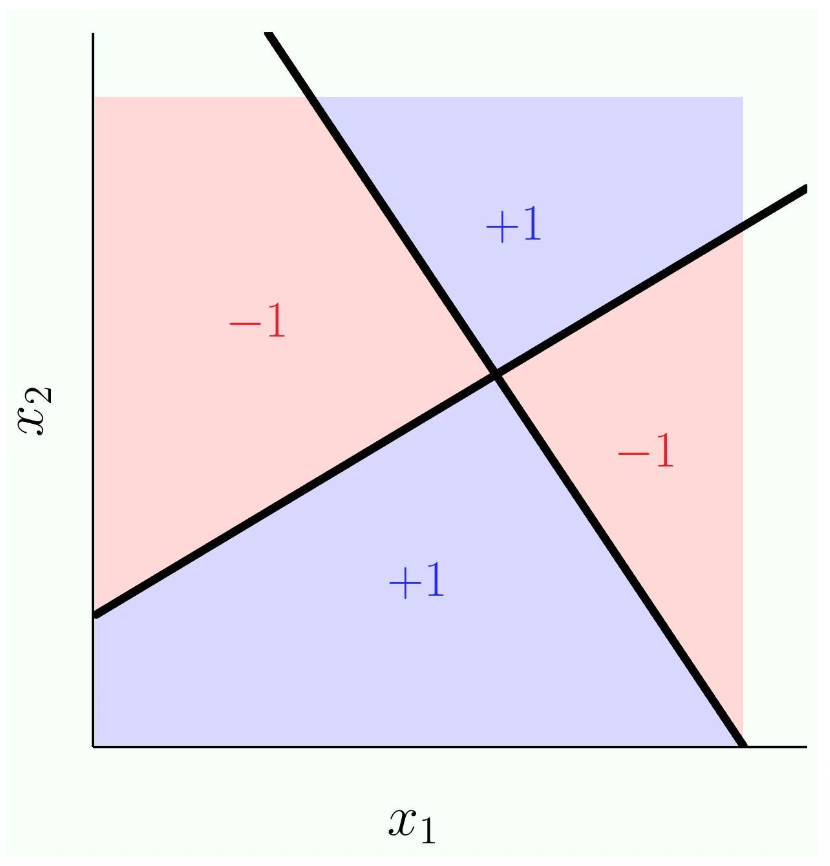
Decomposing XOR
- Exclusive OR:
- Basically means:
- If
and both give you positive or negative, the result is negative (-1). - They need to be different for XOR to output positive (+1)
- If
- So they key here is that we use linear models but we use multiple of them and we put them together
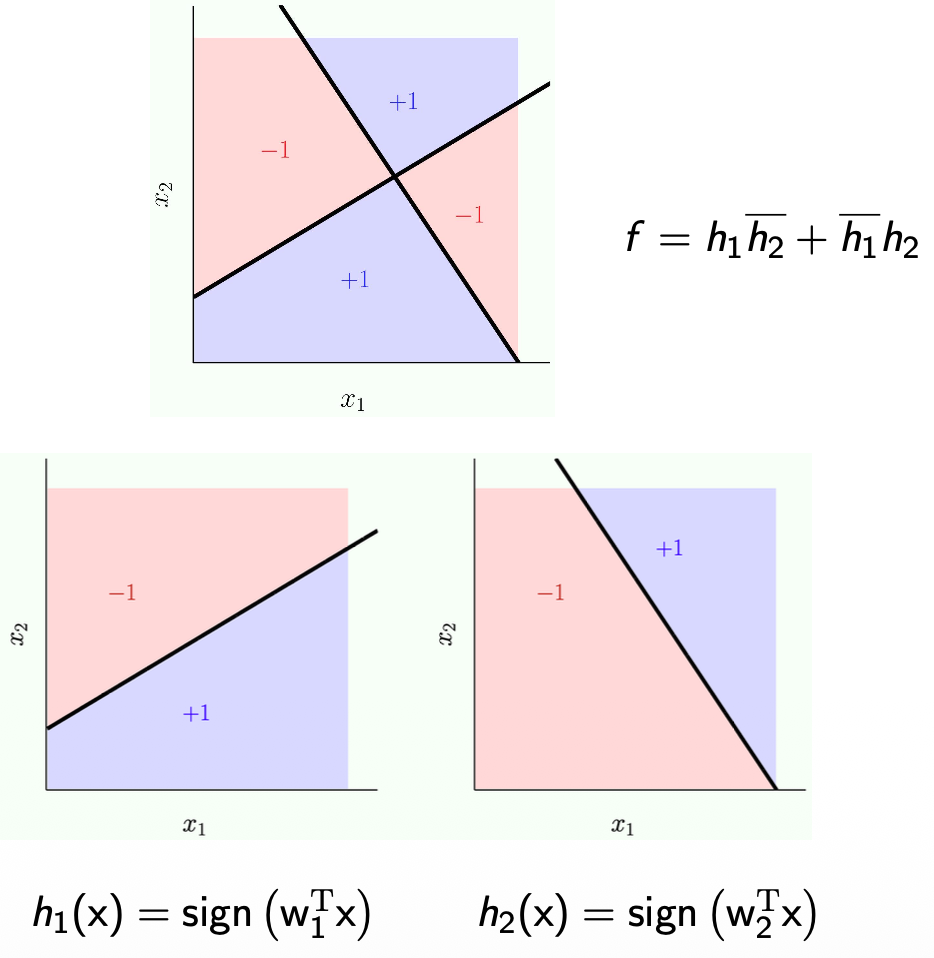
Perceptrons for OR and AND
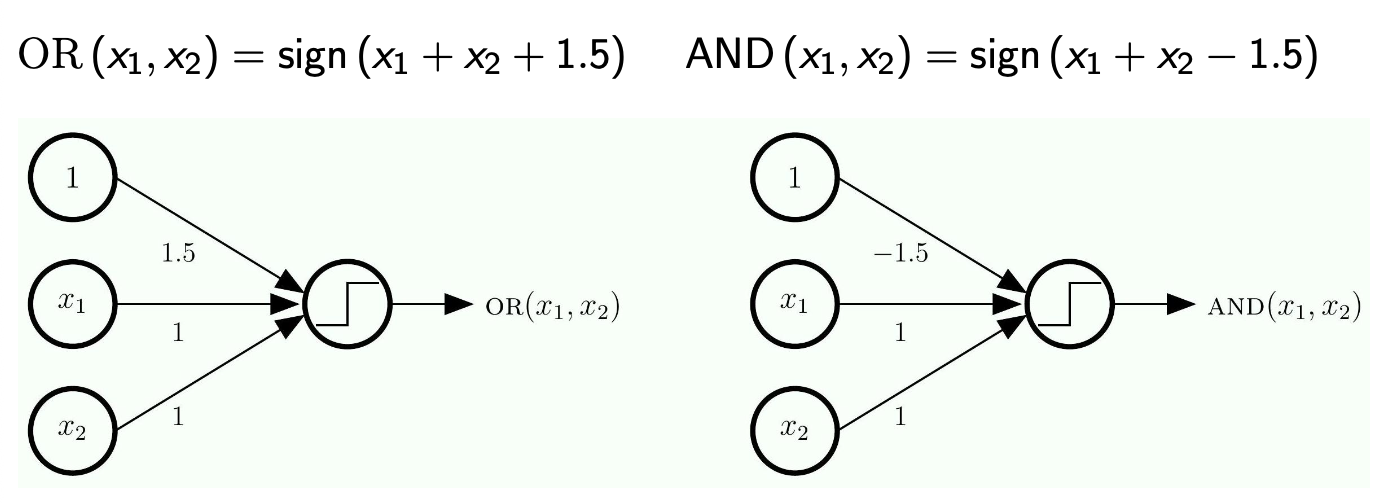
- OR:
- If one or both of
and is positive, then OR is positive - Why +1.5?
- It is just needed to represent OR
- It will just represent the truth table.
- The input for
and is just +1 or -1
- If one or both of
- AND:
- If both
and are positive, then AND is positive
- If both
Representing
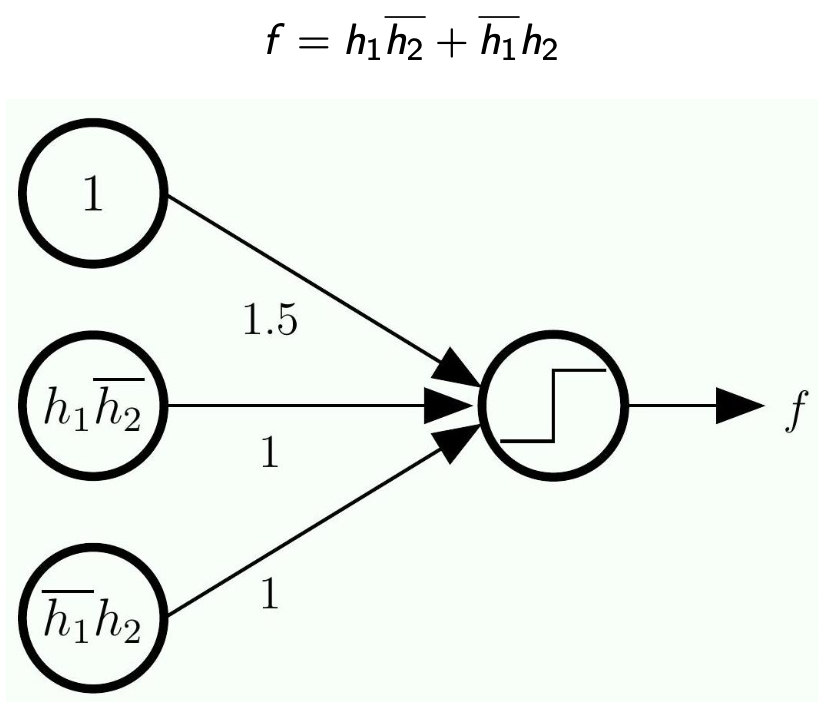
- Here we work backward because we are given
- We need to expand each of
- Here,
is the input and the output is
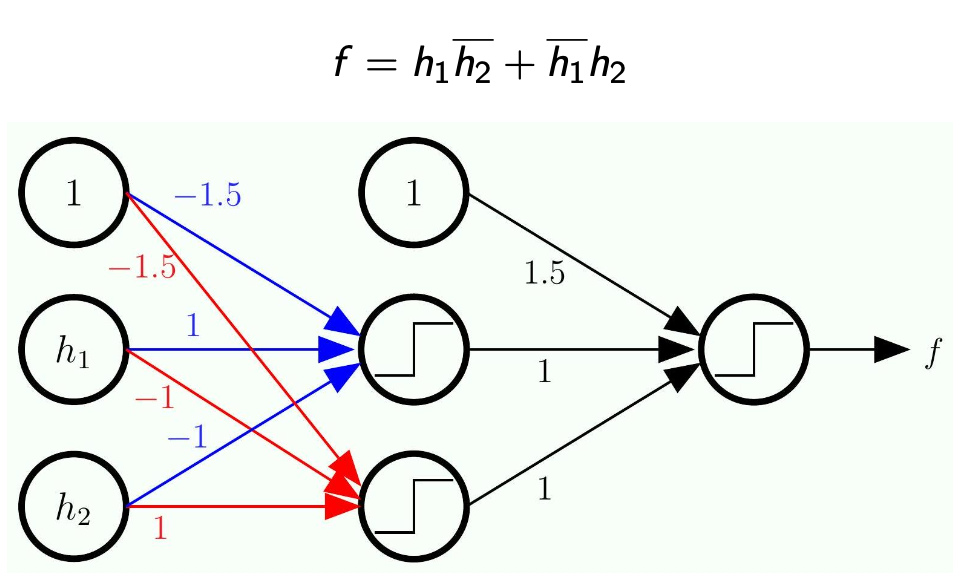
- The next step is to expand each of
- Note that each of
is a linear model of the input
- Note that each of
- The -1.5 will eliminate the term we added to implement OR/AND
- Note the bar on the top means
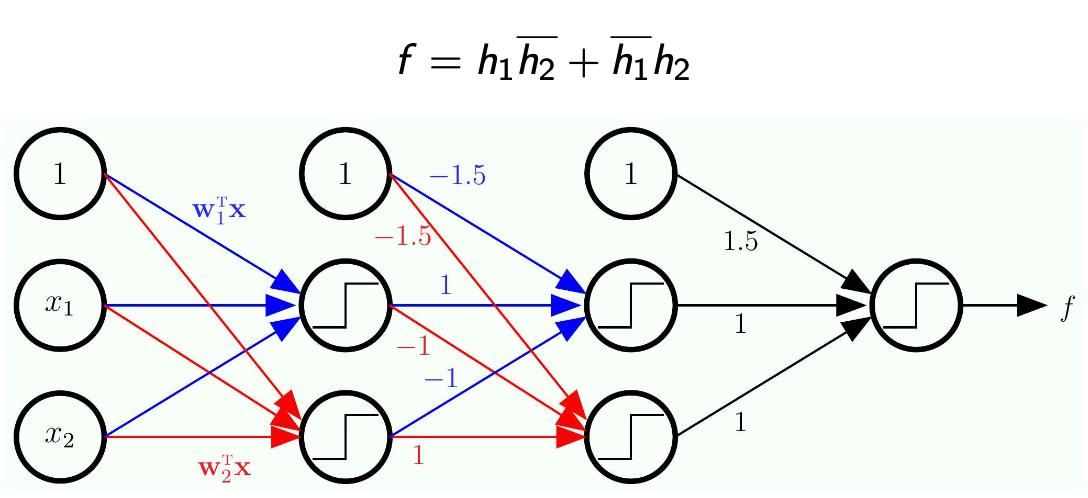
-
Now, since we know each of
is a linear model of the inputs and , then we decompose even more -
Note how this became a network with multiple layers!
-
Nothing is trained here
- This is just a completely hardwire network
- Solves problems that linear models cannot solve by their own
-
Will this method enable us to do more complex models? (something more complex than
) - Yes! you can always convert any logic function into this form
- As long as you can convert to this standard form you will be used to use a network just like this
- The logic form will just look longer
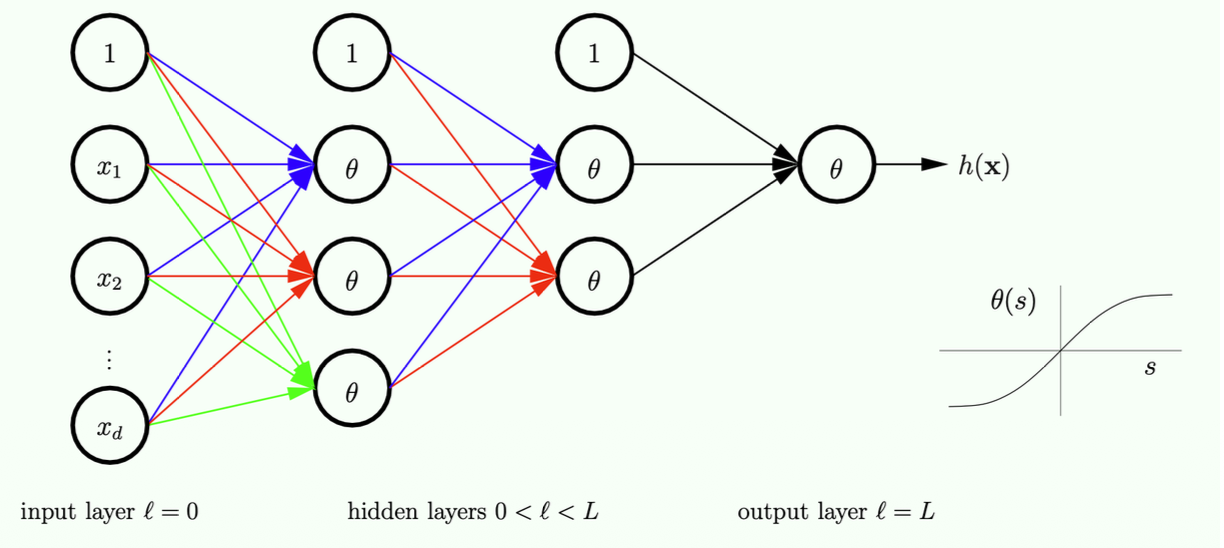
The Multilayer Perceptron (MLP)
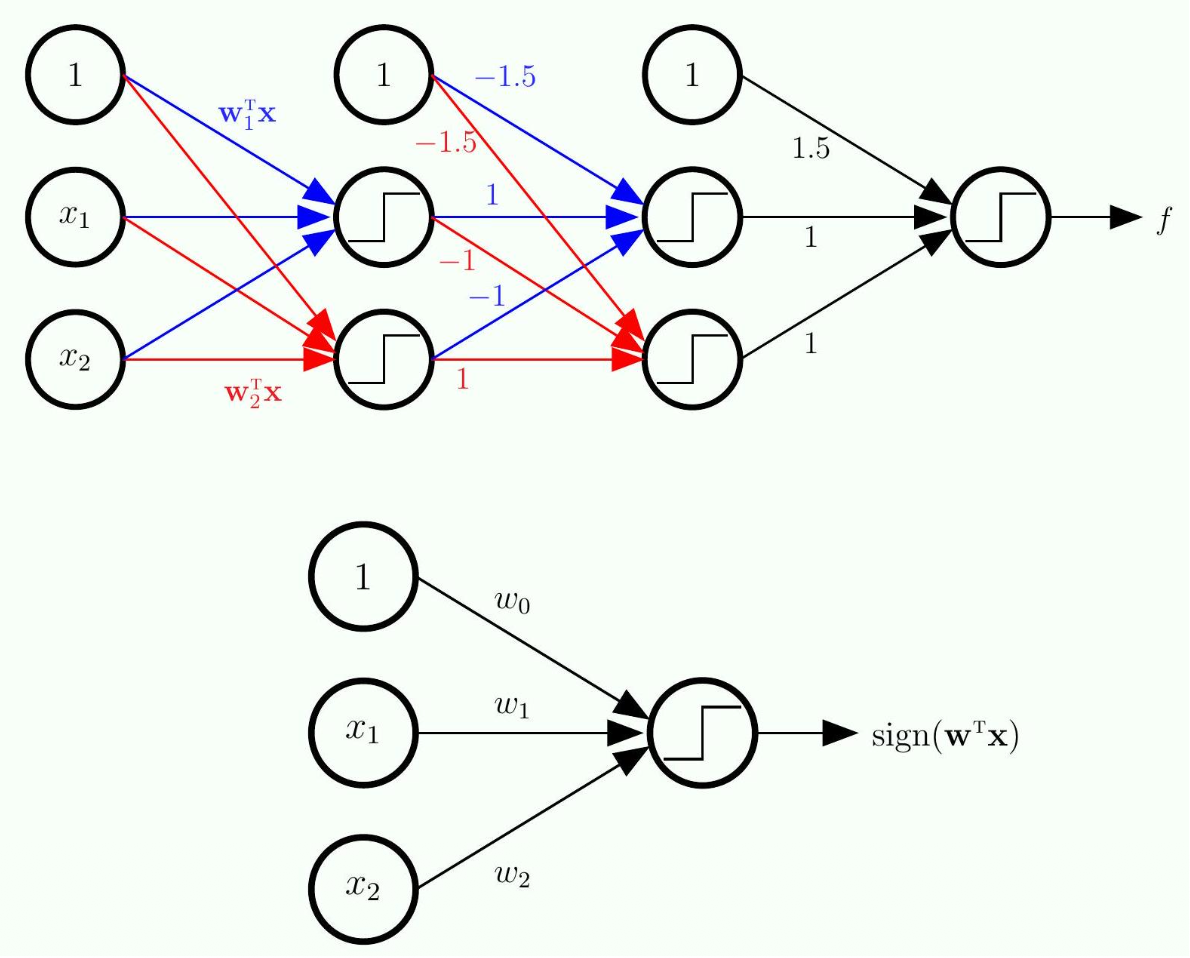
- More layers allow us to implement
- These additional layers are called hidden layers
Universal Approximation
- Any target function
that can be decomposed into linear separators can be implemented by a 3 -layer MLP. - A sufficiently smooth separator can "essentially" be decomposed into linear separators.
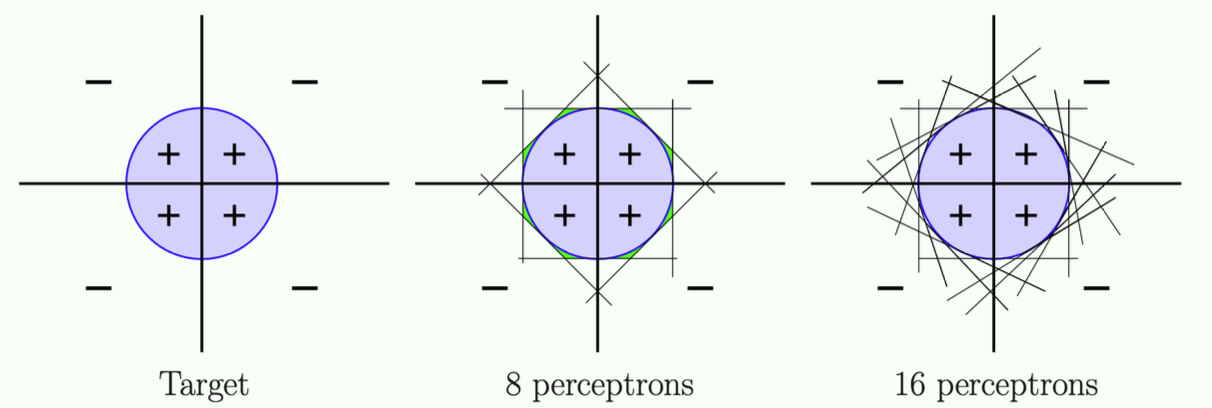
Theory:
- More units/More linear models -> more accurate predictions
The Neural Network
is not smooth (due to sign function), so cannot use gradient descent. gradient descent to minimize .
needs to be differentiable - This function has been used for many years, until recently we changed this, but we will talk about this later
- Note: we use training data to determine all the weights here.
- The question is how do we obtain those connection weights?
- If I have this values on the left, how do we compute the values on the right (on the next layer)
- The "1" on each layer is essentially the threshold term
- That is why this unit will have no input, but will have an output of a fixed value
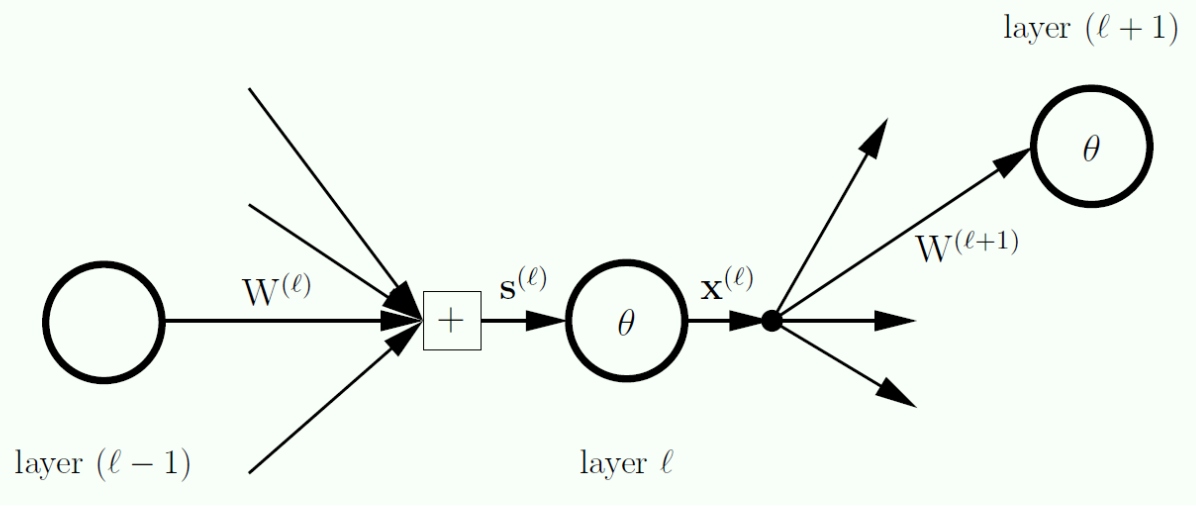
Zooming into a Hidden Node
layer
layers
layer
Notes:
- What are the operations to move between layers?
- For each layer we have a signal (
) go into a particular layer - For each layer we want to put the inputs for each unit into a vector, this vector is called
- Note that
does not consider the bias term
- Note that
- Summary: each layer has an input vector, and an output vector
- At the end we will build a matrix where each row is one column (one layer)
- What would be the size of this matrix?
- This will be on the exam!
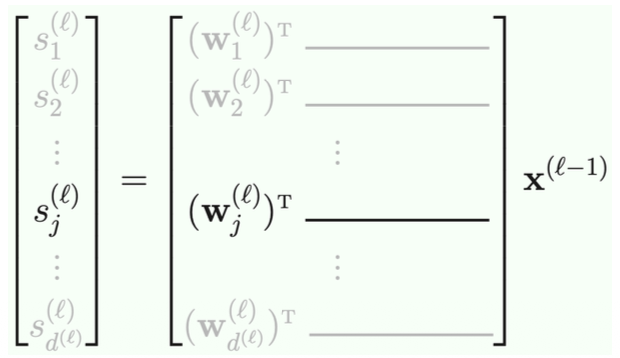
The Linear Signal
Input
The question:
- If I have the input for one layer, how do we calculate the output?
- What is the operation? This is
- We need to take a vector and apply
to every element (element-wise product with )
- We need to take a vector and apply
- What is the operation? This is
- Now, If I know the output values for this layer, how do we calculate the input values for the next layer?
- If you look at the graph, the input of every unit depends on the outputs of the previous layers, but how do we do this?
- What else do we need? -> the weights
- We need to take 1 column from the weights matrix.
- Remember the rows of the weights matrix is composed of the previous layer number of of units as rows and the next layer number of units as columns
- For example between the second (1,
, , ) and third layers (1, , ) in the example above we will have a 4 * 2 matrix - In order to multiply the weights times the
vector you need to do to account for the different number of rows and columns on each vector/matrix
- For example between the second (1,