06 - Multi-Layer Perceptron-Networks
Class: CSCE-421
Notes:
"Now we are talking about something that is not linear"
XOR: A Limitation of the Linear Model
The Math
- Linear model: just 2 layers: input layer and output layer
- One way to make this model not linear is to make it wider (still 2 layers)
- This is called kernel methods
- How to make it wider? you make the input vector to be larger?
- Usually we do not count the softmax layer
- The way to make it wider is to apply
- Now
is a wider vector - This model will be not linear in terms of
- Now
- How do we do transformations to a vector
? - We apply
transformations is a vector that makes the components be multiplied by some other components. - You end up increasing the dimension of
- We apply
- In training, you only need this: $$\phi^T(x_i)\phi(x_j) = (x_i^Tx_j)$$
- The pairwise inner product with
- The pairwise inner product with
- There is a more efficient way to do this, which is deep learning (making a model to be deep)
- Kernel methods = use pairwise inner product
- Can be computed very efficient
The Meaning
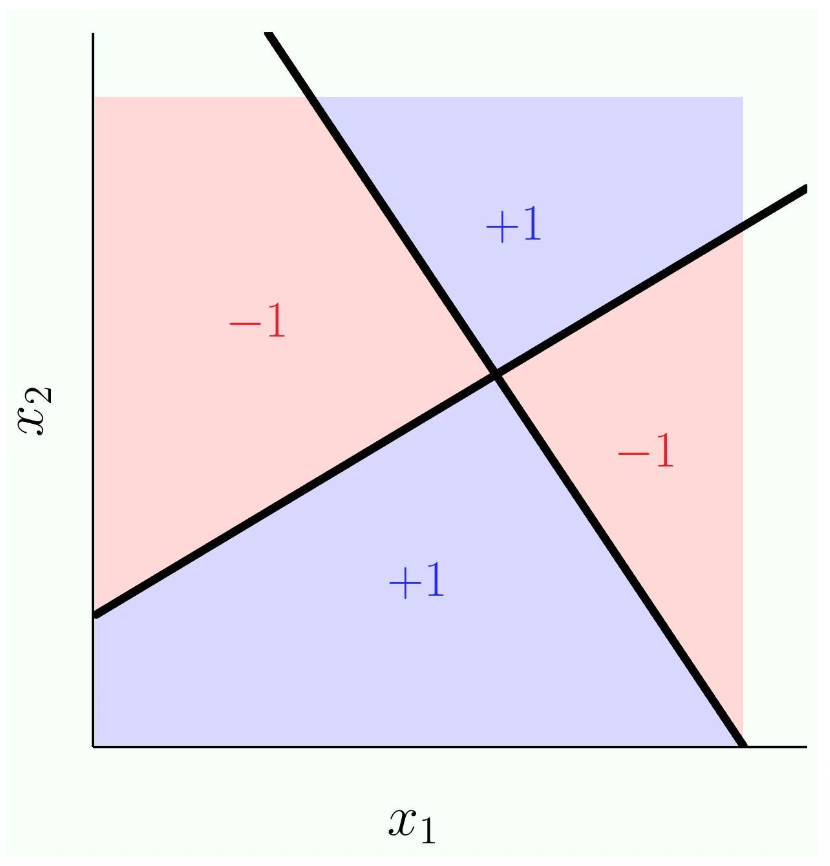
1. The Problem: The XOR Limitation Up until now, you have been using simple 2-layer linear models (an input layer
However, imagine the Exclusive OR (XOR) problem. In a 2D graph, suppose the top-left and bottom-right corners are
To solve non-linear problems like XOR, we have two main choices: make the model "wider" or make it "deeper".
2. Solution 1: Making it "Wider" (Feature Transforms & Kernel Methods) We already explored making models "wider" in the previous chapter on Polynomial Curve Fitting.
- Feature Transform (
): Instead of using the raw input , we apply a mathematical transformation to stretch into a much larger, higher-dimensional vector (e.g., by multiplying and together to create new features). Because the input vector is now physically wider, a linear model has more dimensions to work with and can easily draw a flat plane through the wavy data. - The Kernel Trick: Making vectors infinitely wider takes up massive amounts of computer memory. Your notes mention a shortcut: Kernel Methods. In training algorithms like Support Vector Machines, the algorithm only ever needs to multiply vectors together using a dot product. Instead of computing a giant
and a giant and multiplying them, mathematicians discovered formulas that calculate their exact inner product directly from the original tiny vectors. This is called the "pairwise inner product," and it allows computers to efficiently solve non-linear problems without actually building the giant "wide" vectors.
3. Solution 2: Making it "Deeper" (Deep Learning) Instead of relying on complex math tricks to expand
Decomposing XOR
The Math
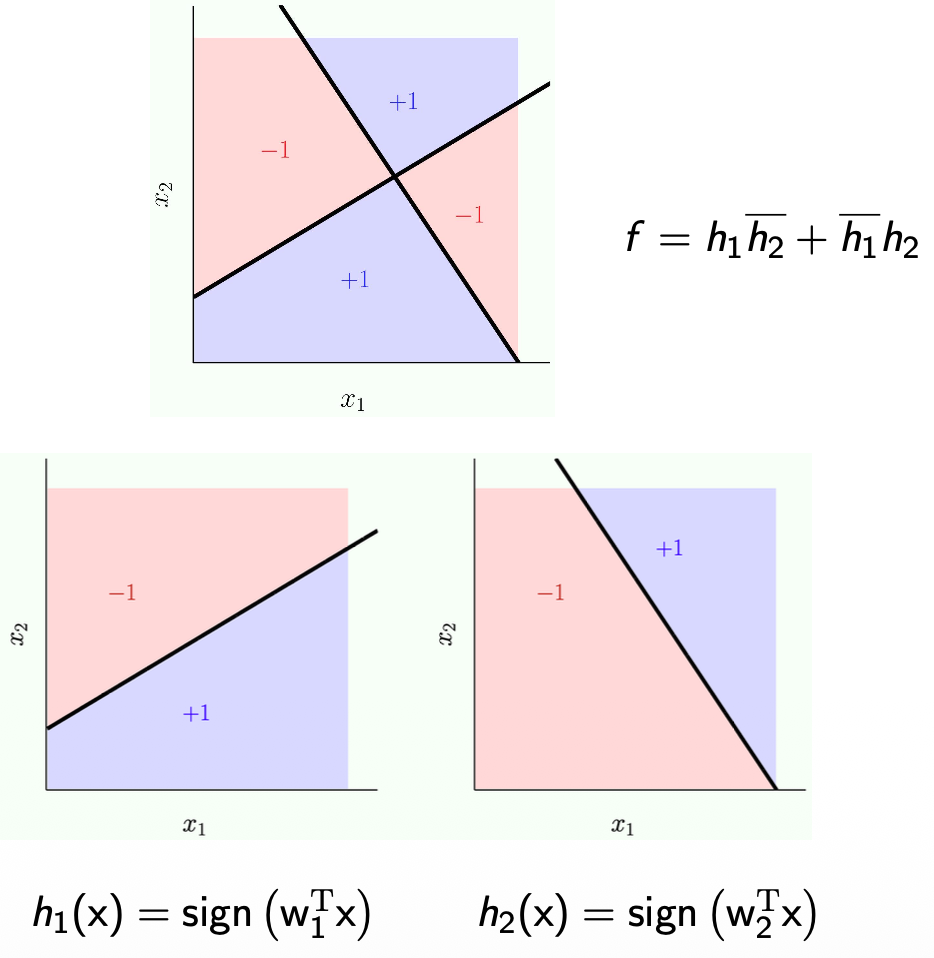
- Exclusive OR:
- Basically means:
- If
and both give you positive or negative, the result is negative (-1). - They need to be different for XOR to output positive (+1)
- If
- So they key here is that we use linear models but we use multiple of them and we put them together
The Meaning
Decomposing XOR These notes prove how multiple linear models can solve XOR using the logic formula:
and are just two entirely separate, standard linear models (two different straight lines drawn on the data). - The overline (like
) just means "NOT" (or the opposite/negative outcome). - The formula dictates that the overall final output
will only be positive ( ) if and output different answers. - If both
and give a positive answer, or if both give a negative answer, the final outcome is negative ( ).
By training two simple linear lines (
Perceptrons for OR and AND
The Math
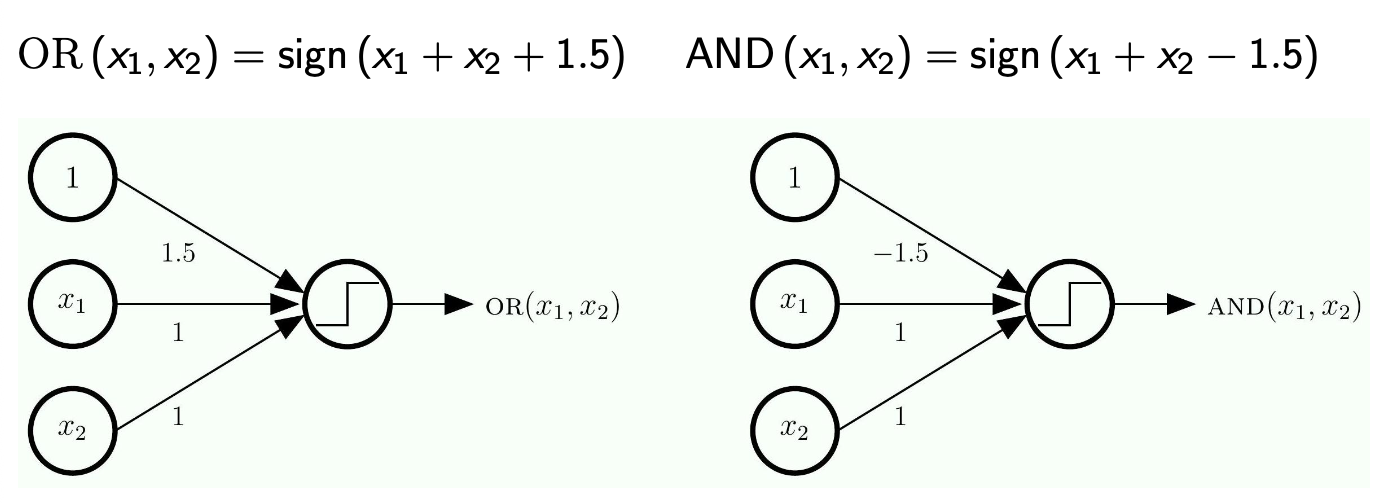
- OR:
- If one or both of
and is positive, then OR is positive - Why +1.5?
- It is just needed to represent OR
- It will just represent the truth table.
- The input for
and is just +1 or -1
- If one or both of
- AND:
- If both
and are positive, then AND is positive
- If both
The Meaning
Logic Gates as Simple Perceptrons In the previous slide, we learned that a single linear model cannot solve the XOR problem. However, a single linear model can easily solve basic logic gates like OR and AND. Let's look at how the math works when our inputs (
- The OR Perceptron:
- If both are False (
): . The sign is (False). - If one is True (
): . The sign is (True). - If both are True (
): . The sign is (True). - Result: It perfectly mimics an OR gate!
- If both are False (
- The AND Perceptron:
- If one is True (
): . The sign is (False). - If both are True (
): . The sign is (True). - Result: It only outputs True if both are True, perfectly mimicking an AND gate.
- If one is True (
Representing
The Math
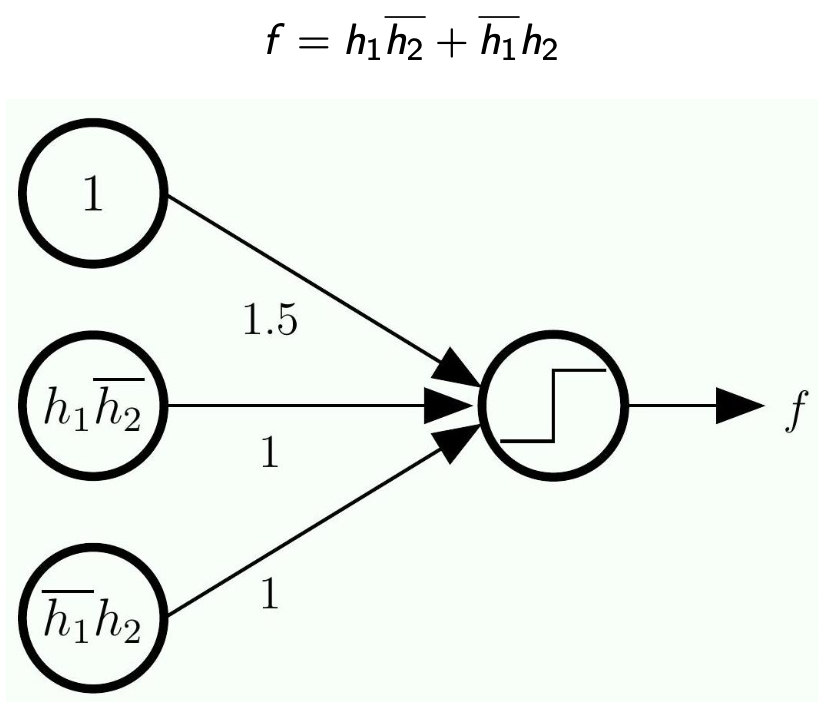
- Here we work backward because we are given
- We need to expand each of
- Here,
is the input and the output is
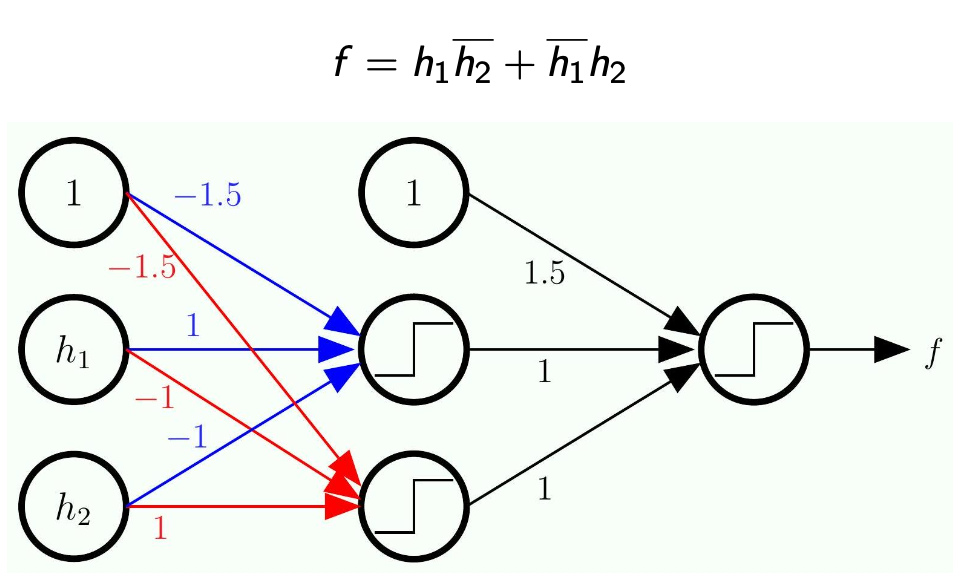
- The next step is to expand each of
- Note that each of
is a linear model of the input
- Note that each of
- The -1.5 will eliminate the term we added to implement OR/AND
- Note the bar on the top means
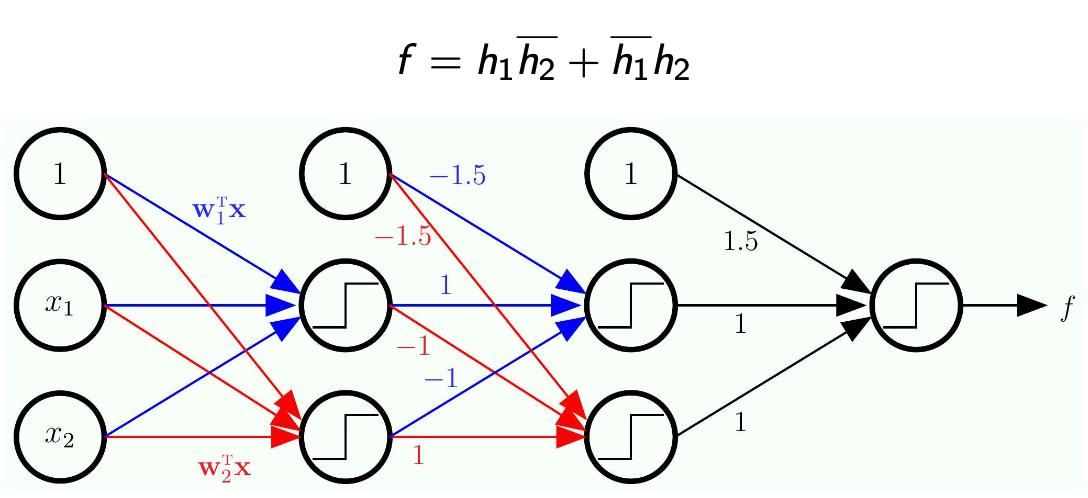
-
Now, since we know each of
is a linear model of the inputs and , then we decompose even more -
Note how this became a network with multiple layers!
-
Nothing is trained here
- This is just a completely hardwire network
- Solves problems that linear models cannot solve by their own
-
Will this method enable us to do more complex models? (something more complex than
) - Yes! you can always convert any logic function into this form
- As long as you can convert to this standard form you will be used to use a network just like this
- The logic form will just look longer
The Meaning
1. Representing
- Step 1: We calculate our two base linear boundaries (
and ) from the original inputs and . - Step 2: We pass those predictions into a new set of perceptrons acting as AND/OR gates.
- Step 3: The
and you see inside the circles in your diagram are simply the bias weights ( ) for those specific neurons, perfectly calibrated to execute the OR and AND logic we proved above. The minus signs on the connections act as the "NOT" ( ) operation.
2. Hardwiring vs. Learning Your notes highlight a very important point: "Nothing is trained here. This is just a completely hardwire network". At this stage, we have manually calculated exactly what the weights and biases must be (like the
The Multilayer Perceptron (MLP)
The Math
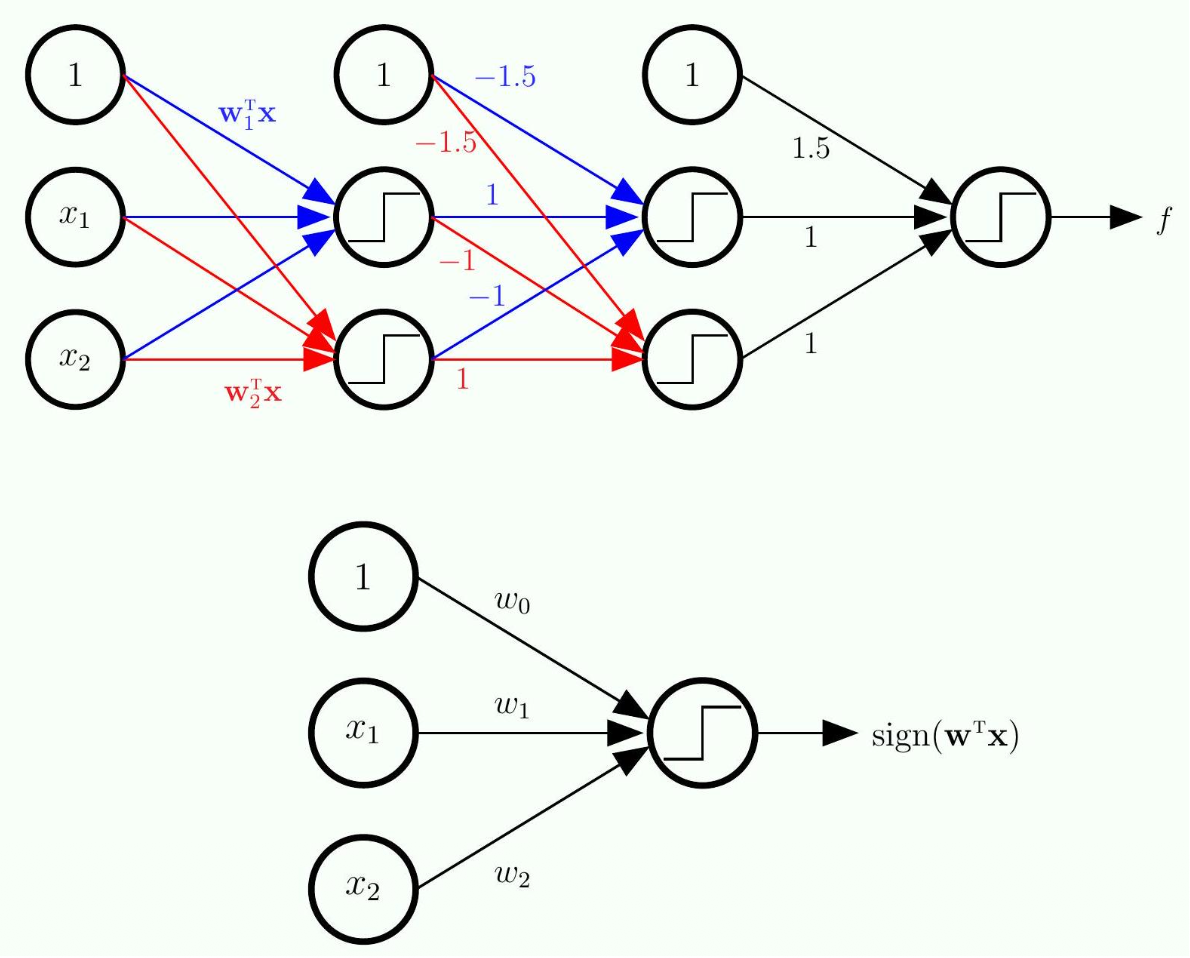
- More layers allow us to implement
- These additional layers are called hidden layers
The Meaning
The Multilayer Perceptron (MLP) and Universal Approximation: By feeding the output of one linear model into the input of another, you have created a Multilayer Perceptron (MLP).
- Hidden Layers: The original data is the Input Layer. The final prediction is the Output Layer. Every layer of neurons we sandwich in the middle is called a Hidden Layer.
- Why does this matter? You asked in your notes: "Will this method enable us to do more complex models?" The answer is a resounding Yes. This brings up a famous concept called Universal Approximation.
Universal Approximation
- Any target function
that can be decomposed into linear separators can be implemented by a 3-layer MLP. - A sufficiently smooth separator can "essentially" be decomposed into linear separators.
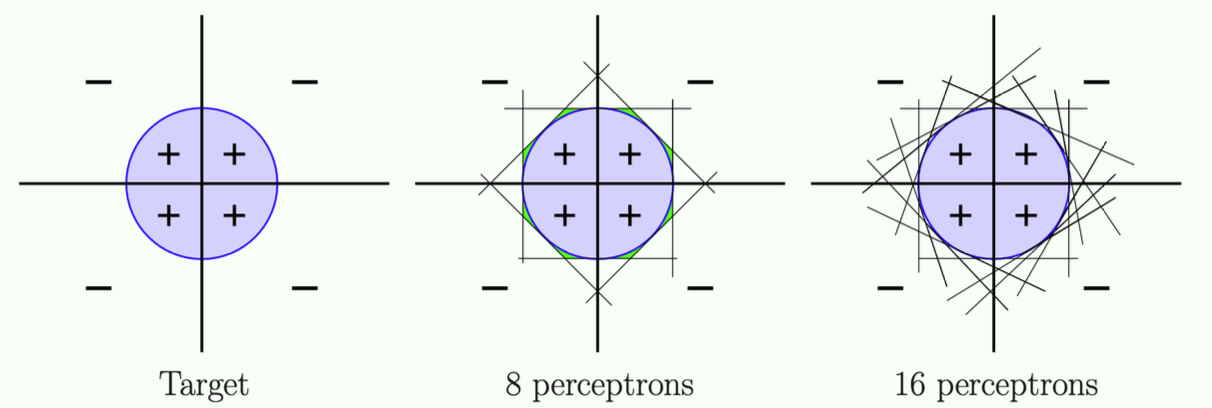
Theory:
- More units/More linear models -> more accurate predictions
- Because you can convert any complex logic function into a combination of basic AND/OR gates, you can technically approximate any target function in the universe just by adding more units and more hidden layers.
The Neural Network
The Math
is not smooth (due to sign function), so cannot use gradient descent. gradient descent to minimize .
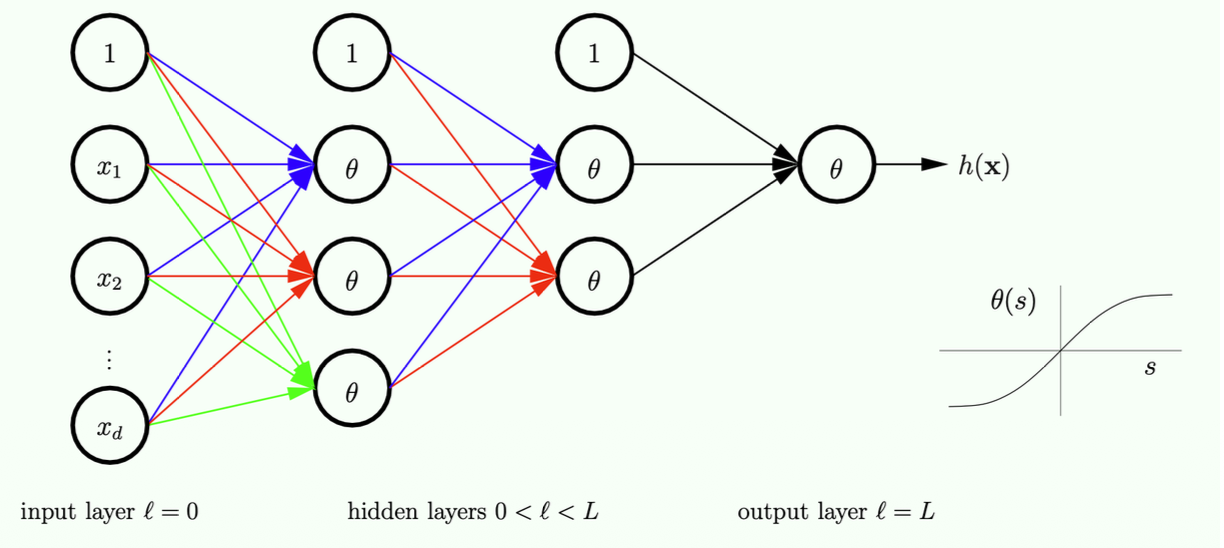
needs to be differentiable - This function has been used for many years, until recently we changed this, but we will talk about this later
- Note: we use training data to determine all the weights here.
- The question is how do we obtain those connection weights?
- If I have this values on the left, how do we compute the values on the right (on the next layer)
- The "1" on each layer is essentially the threshold term
- That is why this unit will have no input, but will have an output of a fixed value
- Note this is not necessarily the most economical way
- If you use more layers, the total number of units might be smaller, that is why people usually do many many layers, even thousands
The Meaning
1. Why
- The standard
function outputs a hard or . It is a flat line with a sudden, sharp cliff at zero. Because it is flat everywhere else, its gradient (slope) is , making Gradient Descent impossible. - The Solution: The
function is an S-shaped curve (a "soft threshold") that smoothly transitions from to . Because it is perfectly smooth and has no sharp cliffs, it is everywhere differentiable. This allows the computer to calculate a gradient and use Gradient Descent to learn the weights automatically, rather than us having to hardwire them manually!
2. The Bias Units (The "1" Nodes) Your notes ask about the "1" on each layer. This is the exact same concept as the dummy coordinate
- Every hidden layer needs its own threshold (bias) to shift the activation function left or right.
- Instead of writing a separate bias term
for every single node, we just add a "fake" node to every layer that always outputs the number . - This node has no inputs (no arrows point into it) because its value never changes. It just outputs
and sends it forward to the next layer to be multiplied by the bias weights.
Zooming into a Hidden Node
The Math
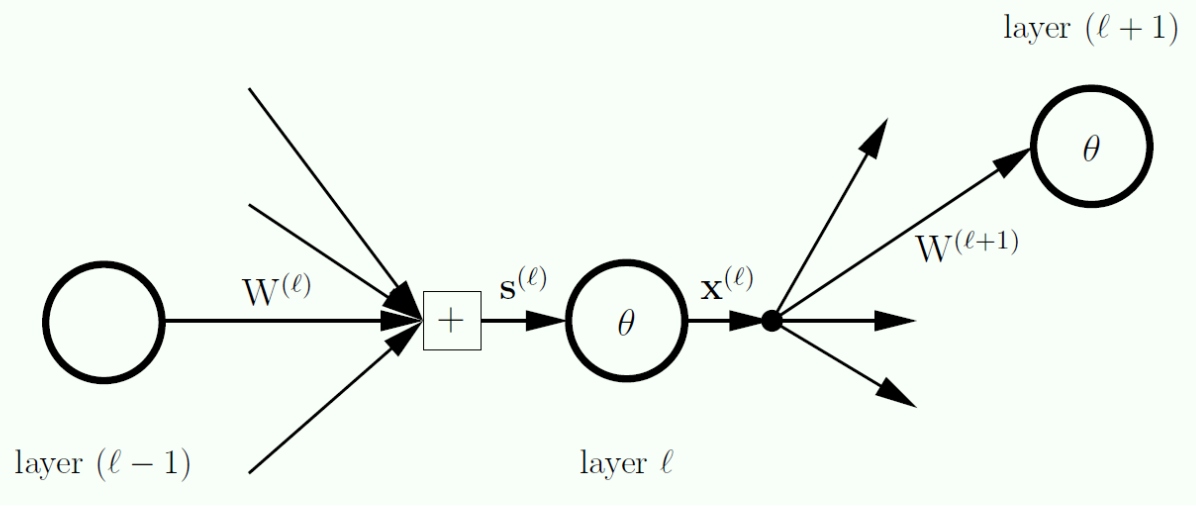
layer
layers
layer
Notes:
- What are the operations to move between layers?
- For each layer we have a signal (
) go into a particular layer - For each layer we want to put the inputs for each unit into a vector, this vector is called
- Note that
does not consider the bias term
- Note that
- Summary: each layer has an input vector, and an output vector
- At the end we will build a matrix where each row is one column (one layer)
- What would be the size of this matrix?
- This will be on the exam!
The Meaning
1. Zooming into a Node (The Pipeline) To understand Neural Network math, you must understand the two-step pipeline that happens at every single layer
- Step 1 (The Signal
): The layer receives raw signals from the previous layer. It multiplies the previous outputs by the weights and adds them up. This results in the dimensional input vector . - Step 2 (The Output
): The layer passes those raw signals through the smooth activation function ( or ) to get the final outputs. We then instantly glue a to the top of this vector for the bias. This makes the output vector slightly larger, with dimensions.
2. Cracking the Exam Question: The Weight Matrix Dimensions Your notes emphasize that the size of the weight matrix
The matrix
- The Rows (Where the data comes from): The matrix needs a row for every single output coming from the previous layer
. How many outputs did the previous layer have? It had regular nodes, PLUS bias node. Therefore, the matrix needs rows. - The Columns (Where the data is going): The matrix needs a column for every single node receiving data in the current layer
. How many nodes receive data? Only the regular nodes (remember, the bias node in layer generates its own "1" and does not accept incoming signals!). Therefore, the matrix needs columns.
The Linear Signal
The Math
Input
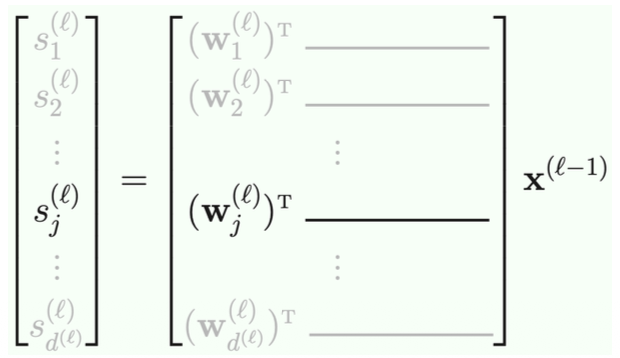
The question:
- If I have the input for one layer, how do we calculate the output?
- What is the operation? This is
- We need to take a vector and apply
to every element (element-wise product with )
- We need to take a vector and apply
- What is the operation? This is
- Now, If I know the output values for this layer, how do we calculate the input values for the next layer?
- If you look at the graph, the input of every unit depends on the outputs of the previous layers, but how do we do this?
- What else do we need? -> the weights
- We need to take 1 column from the weights matrix.
- Remember the rows of the weights matrix is composed of the previous layer number of of units as rows and the next layer number of units as columns
- For example between the second (1,
, , ) and third layers (1, , ) in the example above we will have a 4 * 2 matrix - In order to multiply the weights times the
vector you need to do to account for the different number of rows and columns on each vector/matrix
- For example between the second (1,
- The question here is, given the input of a layer, how do we compute the input for the next layer?
- The operation is simple, you just apply
- Take that vector, apply
element-wise and add a 1 (the threshold) - Of course the output, by convention needs to be a column vector
- This is how you get to the form:
- The operation is simple, you just apply
- All of this will be in the exam
- Will ask for number of parameters and stuff
The Meaning
1. The Two-Step Process of a Neural Network Layer Your notes ask an excellent question: "Given the input of a layer, how do we compute the input for the next layer?" It is crucial to clarify the terminology here. Moving data through a Neural Network happens in a repeating two-step cycle for every layer
- Step A (The Bridge): Multiply the outputs of the previous layer (
) by the weights to get the raw input signals for the current layer ( ). - Step B (The Activation): Apply the activation function (
) to those raw signals to get the final outputs of the current layer ( ). These outputs are then passed to the next layer.
2. Step A: Calculating the Raw Signal (
- Let's look at your example with the
matrix. You mapped this out perfectly! If layer has 3 active nodes + 1 bias node (total 4 outputs), and layer has 2 active nodes, the weight matrix connecting them will have dimensions . - To get the input signal for just one specific node
in the new layer, you take the dot product of the -th column of the weight matrix ( ) and the output vector from the previous layer. - Correction to your linear algebra note: You wrote that you need to do "
". By mathematical convention, because is a column vector, you actually evaluate it exactly as written in the slide: . Transposing the weight matrix into a matrix, and multiplying it by the column vector ( ), results in a neat column vector. This is your raw signal vector .
3. Step B: Calculating the Output (
- You take your raw signal vector
and apply the nonlinear function (like ) to every single number inside it. - Then, you must append the number
1to the very top of the vector. This1becomes the dummy bias coordinate for the next layer's calculations.
4. Exam Prep: Counting Parameters You noted that the exam will ask for the number of parameters. In a neural network, the "parameters" are simply the total number of weights (the individual elements inside the
- For a single layer transition, the number of parameters is exactly the number of rows multiplied by the number of columns in
. - Formula:
. - Example: For your
matrix transition, there are exactly parameters (weights) to learn for that specific layer.
Forward Propagation: Computing
Forward propagation to compute
[Initialization]
- for
to do [Forward Propagation]
- end for
[Output]
Notes:
- You have x, where you want to make preditions
- Input layer is x(0), (there is no
in the input layer) - To compute the input to the next layer we apply
, then to get to the next layer you apply , and so on, you repeat this process. - There are 2 operations to reach a next layer
Minimizing Ein
The Math
/CSCE-421/Visual%20Aids/Pasted%20image%2020260211234601.png)
Using
Notes:
- Now this is about prediction.
- A backward propagation is to adjust weights after a training process and then you need to do forward propagation
- The cost of training the network using a simple example is twice the price of doing a prediction
- Given some samples, how do you train your network?
- We will write a loop and iteratively update each of the
weights.
The Meaning
1. The Objective: Minimizing the Error (
- Why
? The slide reminds us that we must use a smooth activation function like (or the logistic sigmoid ) instead of a hard sign()threshold. If we used a hard step function, the error landscape would be a flat plateau with sudden cliffs. The gradient (slope) would be exactly zero almost everywhere, meaning the computer wouldn't know which way to step. Becauseis smooth, becomes differentiable, allowing us to roll down the hill to a local minimum.
2. Correcting your note: The Training Cycle In your notes, you wrote: "A backward propagation is to adjust weights after a training process and then you need to do forward propagation." It is important to get the order of operations exactly right for your exam. One single step of training actually happens in this exact order:
- Forward Propagation: Pass a data point
through the network to get a prediction , and calculate how wrong it is (the error). - Backward Propagation (Backprop): Use the Chain Rule to calculate the gradient (the slope) of that error with respect to every single weight in the network.
- Weight Update (Gradient Descent): Adjust the weights by taking a small step in the negative gradient direction.
- Note on Computational Cost: You correctly noted that training is about twice as expensive as predicting. Making a prediction requires one pass (Forward). Training requires both a Forward pass (to get the values) and a Backward pass (to compute the derivatives/slopes).
Gradient Descent
The Math
Notes:
- Think about the
to be the collection of all weights. - The key here is still how to compute the derivative, then you plug in
and move in a negative direction. is pretty much empirical, and is pretty much this way for all training models, but the hard part is the gradient part.
The Meaning
The Gradient Descent Update Rule Because a neural network has multiple layers, the "weight" parameter
(Learning Rate): As you noted, this is chosen empirically (often through trial and error or validation). It determines how big of a step we take. (The Gradient): This is the massive matrix of slopes for every single weight in the network. Finding this is the hardest part of Deep Learning.
Gradient of Ein
The Math
We need
Notes:
- To compute the gradient, pretty much you need to repeatedly use the chain rule (Computing this derivative is nothing but chain rule)
- Instead of going through all the details we will just review the results intuitively.
- Again, you need to know if we have a loss function Ein, you compute the loss function of every sample and then you do a summation of all of those
- If you can get the loss for a single sample, then you can just do summation of all the samples to get the total loss
- We just need to get the gradient of a single sample and then just do a summation.
The Meaning
Divide and Conquer: The Gradient of One Sample How do we calculate the derivative for a massive network over a dataset of thousands of images? The slide shows a brilliant mathematical shortcut: Divide and Conquer.
The total error
Algorithmic Approach
The Math
sensitivity
Notes:
- We need to derive one more thing, called sensitivity.
- Above is the definition of sensitivity
- It is a vector, and there is a sensitivity for each layer
- It is the partial derivate of the error (just a number) in terms of the partial derivative of each element of
(the input vector into this layer)
- But what does sensitivity measure?
- Look at it element-wise
- Basically it measures how much the input affects the error (e)
- This is essentially the idea of a partial derivative, if you have a unit change of the input, how much the output would change?
- Think of getting the derivative of y = 2x in terms of y?
- It is just 2, this means if the input is increased by one unit, the output is increased by two units.
- If we have unit change in the input, how much will it change on e?
- If the sensitivity for a unit is 0, it will not affect e
/CSCE-421/Visual%20Aids/Pasted%20image%2020260211234850.png)
Notes:
is the connection between two layers - So now we want to know the partial derivative of the error in terms of
- Remember rows come from the previous layer (i), and columns come from the next layer (j)
- What we want to answer is: If this
is changed by a small amount, how much will change? - If we have unit change in each of the
, how much it changes the error?
- If we have unit change in each of the
- What do we need to know to compute this?
- Suppose you know the sensitivity of every layer
- What affects the derivative of
? - If the sensitivity for a unit is large, that means if we have a small change in one entry, the change in error is large, you do not need to consider anything downstream,
- The sensitivity basically tells you everything after this layer encoded into a single vector
- What else is important here?
- If the output unit if (i) has a zero value, and the derivative measure if we have unit change with the connection
, what would happen here? - This output value is multiplied with
, then what would happen to j? There is no change, the derivative is 0.
- If the output unit if (i) has a zero value, and the derivative measure if we have unit change with the connection
- The derivative of
is simply the output value of (i) times the sensitivity value of (j) - If you connect all of that into a matrix you get to:
- How can we obtain
? - Again we are talking about a single sample, because if we can do this for a single sample, we can do this for every sample
- Just use the #Forward Propagation Computing
formula, if you do forward propagation you get the for each layer.
- How can we obtain
- Question:
s are randomly initialized, what happens if we initialize to be all zeroes? what will happen? - In logistic regression you can do that because you only have one layer, but what would be the consequence here?
- This is an exam question, if you have a network of layers, is initializing
to be all zeroes a good idea? - It is not a good idea because if we do it (a zero matrix) in forward propagation, the values on the output will be all zero vectors, and with
, if the input is zero, the output will be zero, so the of the next layer will be all zeros.
- Takeaway: the derivate in terms of W is proportional to the sensitivity.
The Meaning
1. The Goal: Finding the Gradient To train the neural network, we need to know how to adjust every single weight matrix
2. The Chain Rule Split The slide splits the impossible derivative into two manageable pieces multiplied together: $$ \frac{\partial \mathrm{e}}{\partial \mathrm{W}^{(\ell)}} = \frac{\partial \mathrm{s}^{(\ell)}}{\partial \mathrm{W}^{(\ell)}} \cdot \left(\frac{\partial \mathrm{e}}{\partial \mathrm{s}^{(\ell)}}\right)^T $$
- Part 1:
: How much do the weights change the raw signal? Because the raw signal is just , the derivative with respect to is simply the input data from the previous layer. - Part 2:
: How much does the raw signal change the final error? We define this specific piece as a brand new variable: Sensitivity ( ).
3. What is Sensitivity (
- Because
is a vector (one raw signal for every node in layer ), the sensitivity is also a vector. It contains a separate derivative for every single node in that layer. - Your
analogy is spot on. If the sensitivity for a specific node is , it means that if we nudge that node's raw signal up by unit, the total network error will increase by units. - If the sensitivity is
, the network's error is completely "numb" to that node. You could change that node's signal, and the final error wouldn't budge at all. - Note: The
vector acts as a summary. It encodes everything that happens downstream in the network into a single convenient number for each node.
4. Putting it Together (The Matrix Math) When we substitute
- The Logic: To figure out how much to tweak the weight connecting Node A to Node B, you only need to know two things: How strong was the signal coming out of Node A (
), and how sensitive is the error to what goes into Node B ( ). - The Math (Exam Tip!): Remember in your previous notes you learned the dimensions of the weight matrix
are ? Look at the vector multiplication here. You are multiplying a column vector (which has rows) by a transposed row vector (which has columns). In linear algebra, multiplying a column by a row is called an Outer Product, and it perfectly creates a matrix of size ! Every single weight gets its own unique slope calculated instantly.
5. The Formula: Slope = Input
- The Question: "If I tweak this exact weight by 1 unit, how much does my final error change?"
- The Answer: It depends entirely on two things:
(The Signal Strength): How loud is Node shouting? If Node is outputting a , it doesn't matter how much you tweak the weight connecting it to Node . Any weight multiplied by is still . Therefore, if , tweaking the weight has absolutely no effect on the network, so the derivative (slope) is exactly . (The Sensitivity): How much does the final error care about what enters Node ? If the downstream network is highly sensitive to Node , then is large. A small tweak to the weight will cause a massive change in the error.
6. Where do we get these numbers? As your notes point out, you get these two pieces of the puzzle at two different times:
(The Inputs): You get this for free during Forward Propagation. As you pass the image/data through the network to make a prediction, you just save the outputs of every layer in the computer's memory. (The Sensitivities): You calculate these during Backward Propagation (which we will look at in the next slide).
7. CRITICAL EXAM CONCEPT: The "All-Zeros" Initialization Your notes bring up a classic, guaranteed exam question: "What happens if we initialize
Your notes answer this by saying that if
Imagine you use the Logistic Sigmoid function instead, where
- If every single weight is
, then every single node in a hidden layer receives the exact same input signal. - Because they receive the exact same input, they will output the exact same value.
- During backpropagation, they will all calculate the exact same sensitivity (
) and the exact same gradient. - When Gradient Descent updates the weights, it will change every single weight by the exact same amount.
If you have 1,000 hidden nodes, but they all have the exact same weights and do the exact same math, you don't actually have 1,000 nodes—you effectively just have 1 node. The network will never be able to learn different, complex features (like one node looking for edges, and another looking for colors). Therefore, you must initialize weights with small, random numbers to "break the symmetry" so that different nodes can learn different things!
Computing
The Math
Multiple applications of the chain rule:
/CSCE-421/Visual%20Aids/Pasted%20image%2020260211235009.png)
Notes:
- To compute the sensitivity we use backward propagation, we start from the last layer, until we reach the first one.
- All we need to do is given a particular delta, how do we compute the delta from the previous layer
- Delta is a derivate, so we need to backward propagate this derivative, so we are propagating derivatives
- Easier case: Given delta (l), how do we calculate delta (l-1)?
- Basically you need to know the partial derivative to the output
- If we know the partial derivative of the output for this layer , how do we calculate the partial derivative of the input.
- Note you are not propagating the actual value, you are propagating the derivative
- You have to compute the derivative of
to get a function, and then you need to plug in to the value you got from forward propagation
- Why this is important?
- You can see that if you take the derivate of
the derivative will be close to 0. - If your input value to
is very large, your gradient will be close to 0.
- If your input value to
- You can see that if you take the derivate of
- The backward propagation in some units will depend on the forward propagation, that is why we first need to do forward propagation.
- Why is this non-linear function a curve gradient?
- When we talk about
we are talking about element-wise (each unit) - You compute the gradient of
, and the you plug in. - If
has a grater gradient in the output, the input will be close to 0.
- When we talk about
/CSCE-421/Visual%20Aids/Pasted%20image%2020260211235051.png)
Notes:
- How do we backward propagate the W matrix
- It requires two operations
- We need to first forward propagate
- Then we need forward propagation
- The weight (each line) needs to be multiplied with the sensitivity on each unit, then we'll sum them up together and get the derivative
- You are taking the ith row and taking the inner product with each sensitivity (each column). This is represented as a matrix multiplication
- This is because this product eventually becomes a column vector
- Multiply W matrix with the sensitivity vector, but note you are removing the first element.
- The 1 does not need to be backward propagated because there is no input for the "1" entry.
- Note that during prediction time you just need forward propagation, but in training you will need to do forward propagation first, then you need to do backward propagation
- The cost of doing forward propagation is twice the cost of doing backward propagation
- In forward propagation we do matrix multiplication
- In forward propagation we again multiply this W but elementwise?
- This is why training a network is much more expensive.
- The cost of doing forward propagation is twice the cost of doing backward propagation
The Meaning
1. The Big Picture: Passing the Blame Backwards In the previous slide, we learned that to update the weights, we need to know the Sensitivity (
- For the very last layer (the output layer
), this is easy. We know the exact prediction, we know the true answer, so we can directly calculate the error derivative. - But how do we find the sensitivity of the hidden layers deep inside the network? We use Backward Propagation. We start with the sensitivity at the output layer (
) and use the Chain Rule to pass the "blame" for the error backwards through the network: .
2. Breaking Down the Backprop Formula Your slide gives the master formula for how to compute the sensitivity of the current layer (
- Step A: Moving backward across the weights (
). We take the sensitivities of the next layer ( ) and multiply them by the weight matrix connecting the two layers. This calculates how much the outputs ( ) of our current layer contributed to the error. - The Bias Note: Your notes say "Multiply W matrix... but note you are removing the first element." This is what the subscript
means. When we compute the errors, we must discard the sensitivity for the bias node (the "1"). Why? Because the bias node is a hardcoded constant 1. It has no inputs, nothing feeds into it, so we do not backpropagate error through it.
- The Bias Note: Your notes say "Multiply W matrix... but note you are removing the first element." This is what the subscript
- Step B: Moving backward through the activation function (
). Now that we know the error of the output , we need the error of the raw signal (which is what actually is). To go backwards through a function, calculus tells us we must multiply by its derivative: . - The
symbol just means element-wise multiplication. We match up the nodes one by one and multiply their values together.
- The
3. The "Curve Gradient" and the Vanishing Gradient Problem You wrote a brilliant note here: "If your input value to
Let's think about why this is mathematically true and practically dangerous:
- If you use
or the logistic sigmoid function as your activation function, they look like an "S" curve. The middle of the "S" is steep, but the far left and far right ends flatten out completely into horizontal lines. - If a raw signal
is very large (say, or ), it lands on the flat part of the curve. The slope (derivative ) of a flat horizontal line is exactly . - Look back at our Backprop formula: it multiplies by
. If this derivative is , the entire sensitivity becomes . - If
, the weights stop updating (remember the previous slide: ). The network becomes paralyzed and completely stops learning. This is a famous phenomenon in deep learning called the Vanishing Gradient Problem.
The Backpropagation Algorithm
/CSCE-421/Visual%20Aids/Pasted%20image%2020260211235303.png)
Algorithm for Gradient Descent on Ein
/CSCE-421/Visual%20Aids/Pasted%20image%2020260211235351.png)
- This is the whole training process
- The key is the inner for loop, it will compute the gradient
- You do not need to implement this loop in HW2, you will just use pytorch function to do this.
- Can do batch version or sequential version (SGD).
Digits Data
/CSCE-421/Visual%20Aids/Pasted%20image%2020260211235448.png)