Web Archives
Thanks to the Internet Archive's Wayback Machine, we have a unique opportunity to revisit the past and explore the digital footprints of websites as they once were.
What is the Wayback Machine?
The Wayback Machine is a digital archive of the World Wide Web and other information on the Internet. Founded by the Internet Archive, a non-profit organization, it has been archiving websites since 1996.
It allows users to "go back in time" and view snapshots of websites as they appeared at various points in their history. These snapshots, known as captures or archives, provide a glimpse into the past versions of a website, including its design, content, and functionality.
How Does the Wayback Machine Work?
The Wayback Machine operates by using web crawlers to capture snapshots of websites at regular intervals automatically. These crawlers navigate through the web, following links and indexing pages, much like how search engine crawlers work. However, instead of simply indexing the information for search purposes, the Wayback Machine stores the entire content of the pages, including HTML, CSS, JavaScript, images, and other resources.
The Wayback Machine's operation can be visualized as a three-step process:
- Crawling: The Wayback Machine employs automated web crawlers, often called "bots," to browse the internet systematically. These bots follow links from one webpage to another, like how you would click hyperlinks to explore a website. However, instead of just reading the content, these bots download copies of the webpages they encounter.
- Archiving: The downloaded webpages, along with their associated resources like images, stylesheets, and scripts, are stored in the Wayback Machine's vast archive. Each captured webpage is linked to a specific date and time, creating a historical snapshot of the website at that moment. This archiving process happens at regular intervals, sometimes daily, weekly, or monthly, depending on the website's popularity and frequency of updates.
- Accessing: Users can access these archived snapshots through the Wayback Machine's interface. By entering a website's URL and selecting a date, you can view how the website looked at that specific point. The Wayback Machine allows you to browse individual pages and provides tools to search for specific terms within the archived content or download entire archived websites for offline analysis.
The frequency with which the Wayback Machine archives a website varies. Some websites might be archived multiple times a day, while others might only have a few snapshots spread out over several years. Factors that influence this frequency include the website's popularity, its rate of change, and the resources available to the Internet Archive.
It's important to note that the Wayback Machine does not capture every single webpage online. It prioritizes websites deemed to be of cultural, historical, or research value. Additionally, website owners can request that their content be excluded from the Wayback Machine, although this is not always guaranteed.
Why the Wayback Machine Matters for Web Reconnaissance
The Wayback Machine is a treasure trove for web reconnaissance, offering information that can be instrumental in various scenarios. Its significance lies in its ability to unveil a website's past, providing valuable insights that may not be readily apparent in its current state:
- Uncovering Hidden Assets and Vulnerabilities: The Wayback Machine allows you to discover old web pages, directories, files, or subdomains that might not be accessible on the current website, potentially exposing sensitive information or security flaws.
- Tracking Changes and Identifying Patterns: By comparing historical snapshots, you can observe how the website has evolved, revealing changes in structure, content, technologies, and potential vulnerabilities.
- Gathering Intelligence: Archived content can be a valuable source of OSINT, providing insights into the target's past activities, marketing strategies, employees, and technology choices.
- Stealthy Reconnaissance: Accessing archived snapshots is a passive activity that doesn't directly interact with the target's infrastructure, making it a less detectable way to gather information.
Exercise
Challenge 1
How many Pen Testing Labs did HackTheBox have on the 8th August 2018? Answer with an integer, eg 1234.
Enter the page we are looking for (hackthebox.eu) into the Wayback Machine and select 8th August 2018
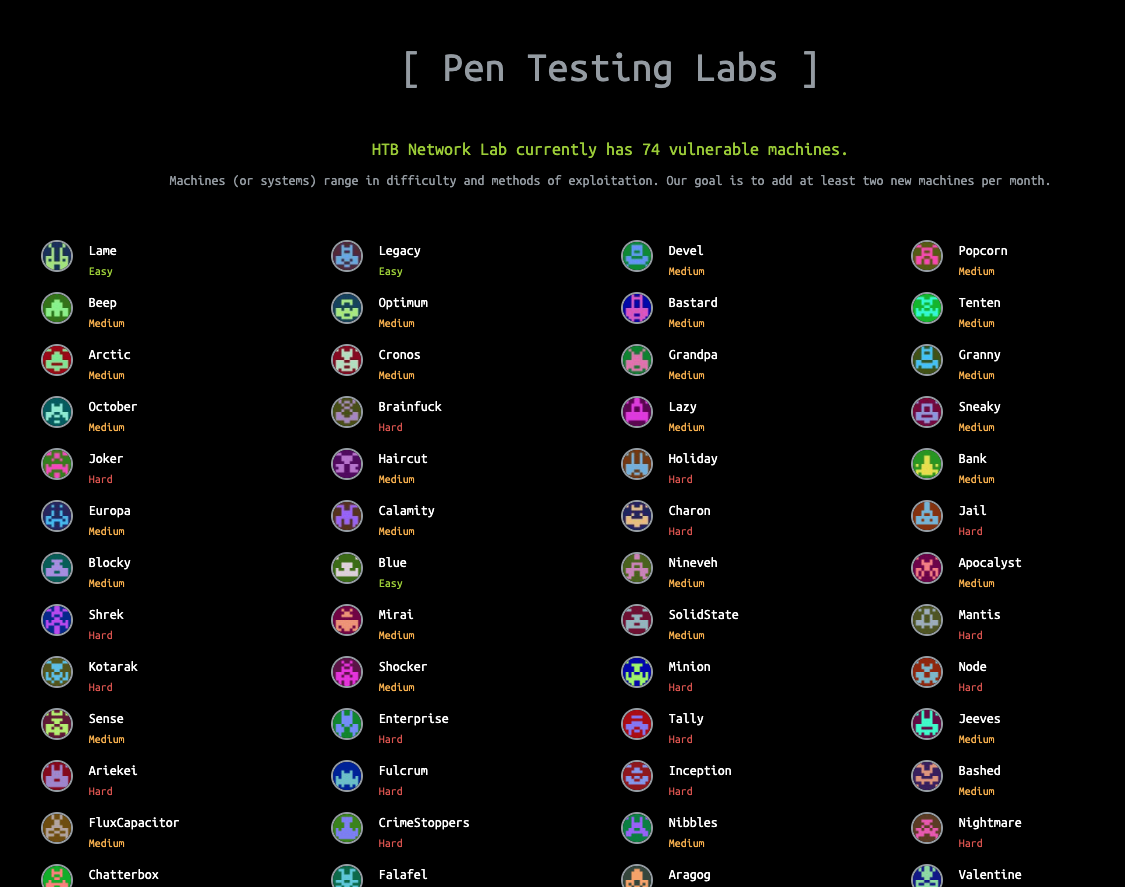
flag: 74
Challenge 2
How many members did HackTheBox have on the 10th June 2017? Answer with an integer, eg 1234.
Enter the page we are looking for (hackthebox.eu) into the Wayback Machine and select 10th June 2017
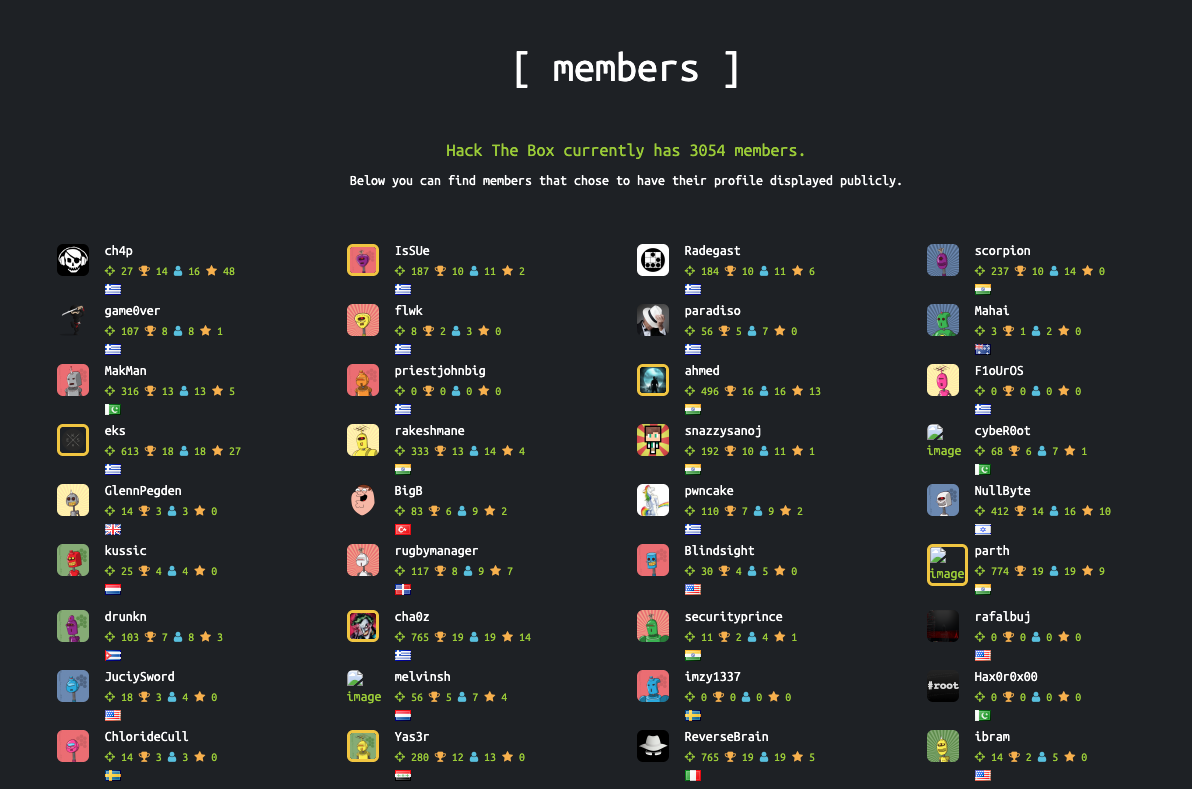
flag: 3054
Challenge 3
Going back to March 2002, what website did the facebook.com domain redirect to? Answer with the full domain, eg http://www.facebook.com/
Enter the page we are looking for (http://www.facebook.com/) into the Wayback Machine and select March 2002
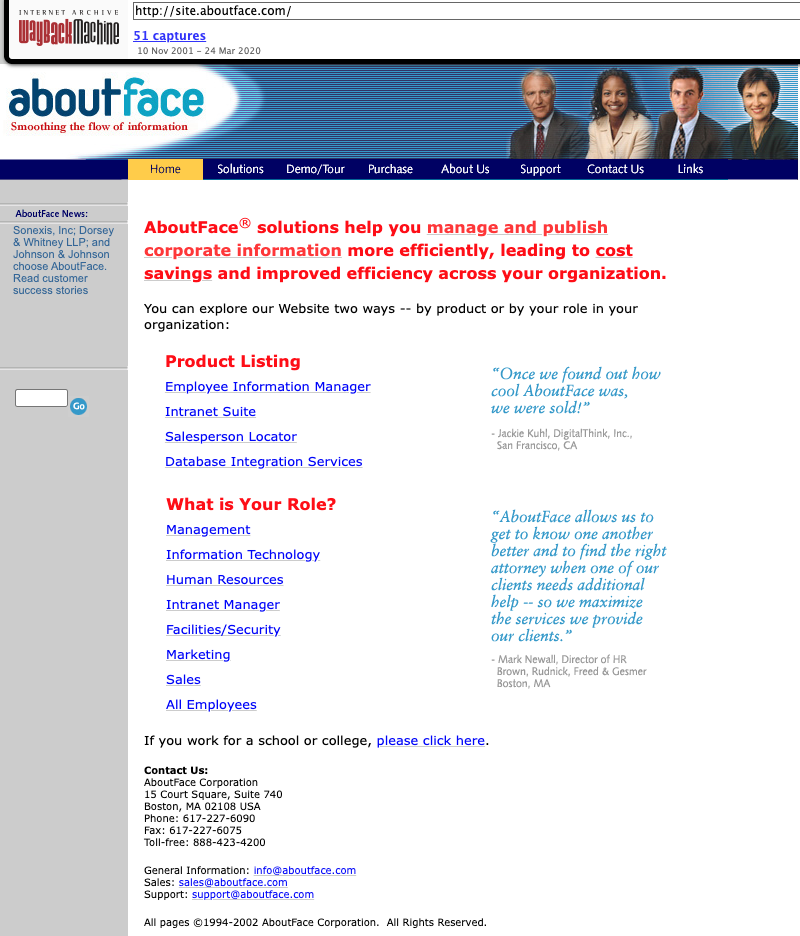
flag: http://site.aboutface.com/
Challenge 4
According to the paypal.com website in October 1999, what could you use to "beam money to anyone"? Answer with the product name, eg My Device, remove the ™ from your answer.
Enter the page we are looking for (paypal.com) into the Wayback Machine and select 13th October 1999
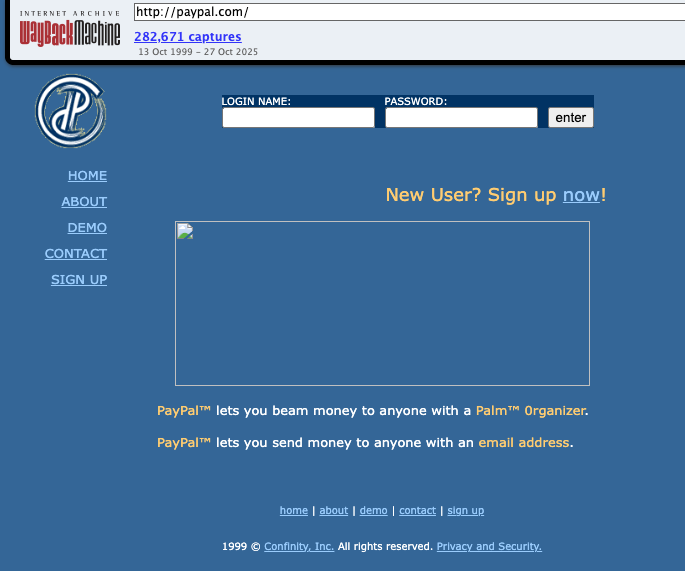
flag: Palm Organizer (paste it, do not type it)
Challenge 5
Going back to November 1998 on google.com, what address hosted the non-alpha "Google Search Engine Prototype" of Google? Answer with the full address, eg http://google.com
Enter the page we are looking for (http://google.com) into the Wayback Machine and select 11th November 1998
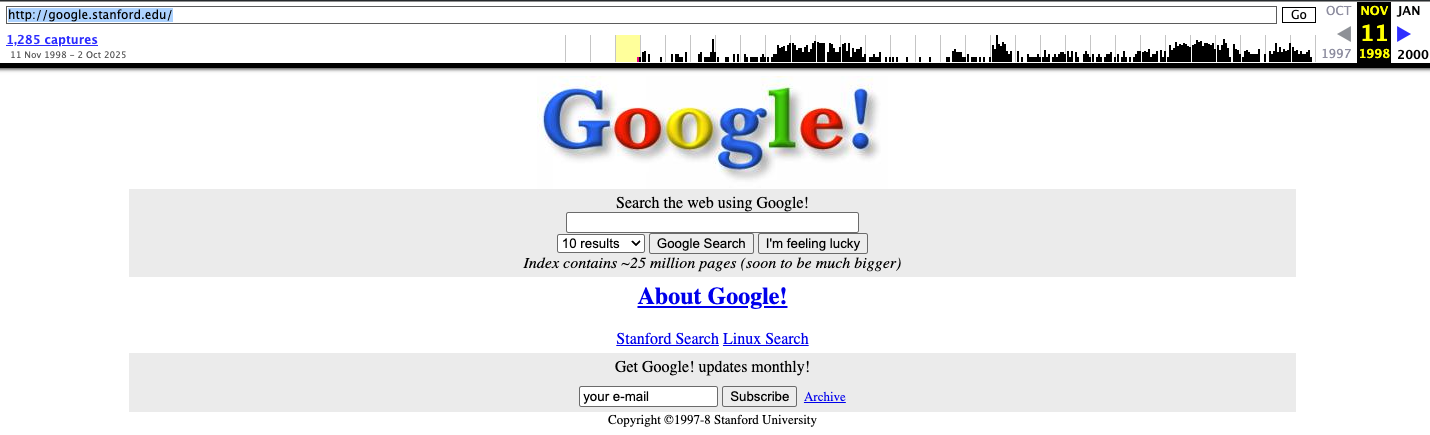
flag: http://google.stanford.edu/
Challenge 6
Going back to March 2000 on www.iana.org, when exacty was the site last updated? Answer with the date in the footer, eg 11-March-99
Enter the page we are looking for (www.iana.org) into the Wayback Machine and select 3rd March 2000

flag: 17-December-99
Challenge 7
According to wikipedia.com snapshot taken on February 9, 2003, how many articles were they already working on in the English version? Answer with the number they state without any commas, e.g., 100000, not 100,000.
Enter the page we are looking for (wikipedia.com) into the Wayback Machine and select 9th February 2003
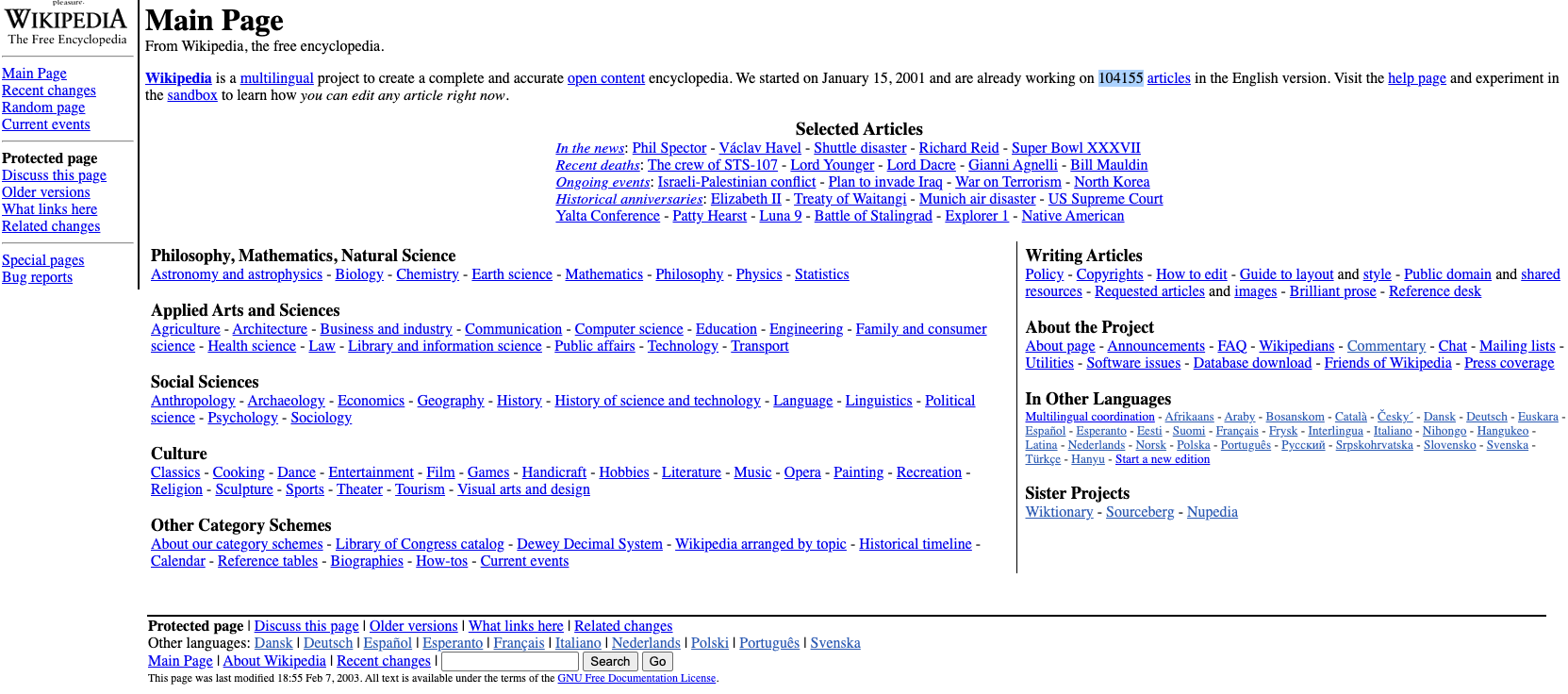
flag: 104155