05 - A Unified View of Loss Functions in Supervised Learning
Class: CSCE-421
Notes:
Intro
- So far we have only talk about two different loss functions and two different type of models, linear regression, and logistic regression.
- The loss is how you measure the difference between a predicted value and the real target (label)
- In Linear regression we use least squares
- In logistic regression we use the cross-entropy loss
- Today we will be dealing with a more general view of loss functions and other considerations
A Unified View of Loss Functions: Binary-Class Classifier
The Math
(1) Given a dataset
- X is our input vector
- y is our labels vector
- Note this is a two-class (binary) predictor
(2) For a given sample
(3) We study the relations between loss values and
- Predict -1 if
is negative - Predict +1 if
is positive - ⟹ Prediction is correct if
- Prediction confidence is large if
is large - ⟹ Prediction is very correct if
- ⟹ Prediction is very wrong if
Notes:
- Our predictions are based on
- If the
is positive you predict (+1), otherwise (-1) - Now after knowing our prediction we can put it the true label with the score. If these two are different, the prediction will be wrong, but if they are equal the prediction will be correct
- Note both
and need to be of the same sign to yield a correct prediction.
- Note both
- If
has a large magnitude, then the prediction confidence is large, you have a high score! - Similarly,
- if
is very positive (much larger than 0) you have a very confident prediction - if
is very negative (much smaller than 0) you have a very wrong prediction
- if
The Meaning
1. The Magic Metric:
We do this by combining two things:
- The true label (
): Either or . - The raw linear score (
): The raw dot product , which can be any number from to .
When we multiply these together to get
- The Sign (Correctness): If the true label
and the score have the exact same sign (both positive or both negative), multiplying them together results in a positive number ( ). This means the model's prediction matches reality. If they have opposite signs, , meaning the model is wrong. - The Magnitude (Confidence): The absolute value
represents how far the data point is from the decision boundary. If it is a huge number, the model is highly confident. : The model is very confident and correct. : The model is very confident and wrong.
Zero-One Loss
The Math
(1) Prediction is correct if
(2) The zero-one loss aims at measuring the number of prediction errors
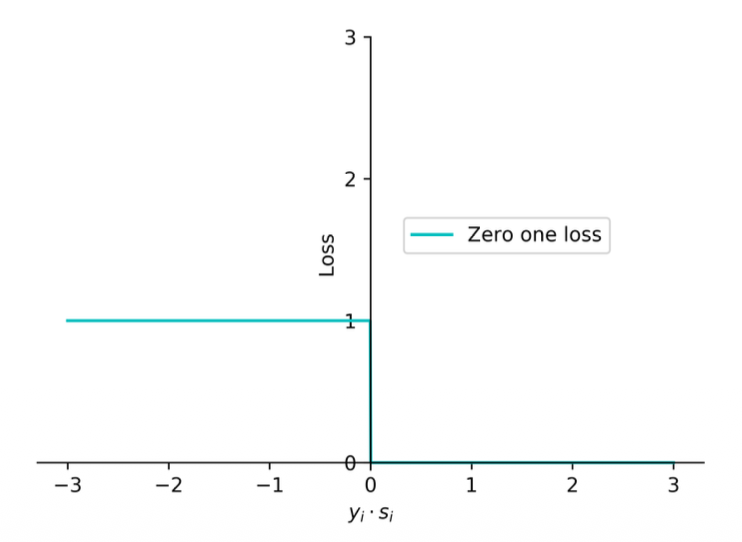
(3) The loss for the entire training data is
Notes:
- The first loss function that we will talk about
- It will be 1 when
is negative and 0 if is positive - What does this loss do?
- We know that any sample below
is wrong and above that is correct - This will just give you an n integer number of how many samples are mis-predicting
- We know that any sample below
- If we want to minimize the training loss
- If we use the zero-one loss we are just minimizing the number of wrong predictions
- This loss function is not commonly used because it is not continuous, you will have to deal with discrete optimization (since there is a jump from 0 to 1)
- The cross-entropy loss is a continuous optimization of this functions
The Meaning
2. The Zero-One Loss (
- If your prediction is correct (
), you get penalty points. - If your prediction is wrong (
), you get exactly penalty point.
To find the total error of your model on the whole dataset, you just average these penalties:
The total Zero-One loss is literally just the percentage of misclassified examples in your dataset.
3. The Problem with Zero-One Loss Your final note highlights the most important takeaway: "This loss function is not commonly used because it is not continuous, you will have to deal with discrete optimization".
Why is this bad? Remember the analogy of Gradient Descent: a ball rolling down a smooth hill to find the minimum. If you graph the Zero-One loss, it is not a smooth hill. It is a perfectly flat line at
To use Gradient Descent, we must replace this "stair-step" cliff with a smooth, curved approximation (like the Cross-Entropy Log Loss) that a computer can easily roll a ball down.
Perceptron loss
The Math
(1) The zero-one loss incurs the same loss value of 1 for all wrong predictions, no matter how far a wrong prediction is from the hyperplane.
(2) The perceptron loss addresses this by penalizing each wrong prediction by the extent of violation. The perceptron loss function is defined as
(3) Note that the loss is 0 when the input example is correctly classified. The loss is proportional to a quantification of the extent of violation (
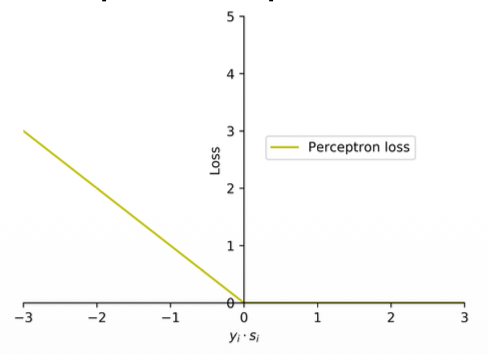
Notes:
- I f
is positive then you have a positive value as max, if is negative then you will have a negative value as max? - Somehow this loss seems to work right
- It will not give you the number of mis-predictions
- Is an approximation of the zero-one function
The Meaning
1. Perceptron Loss: Measuring "How Wrong" You Are In the previous slide, we saw that the Zero-One loss is flawed because it gives a flat penalty of
The Perceptron Loss fixes this by penalizing the model based on the extent of the violation.
- Fixing your note: You asked, "If
is positive then you have a positive value as max, if is negative then you will have a negative value as max?" This is incorrect. Let's look closely at the formula: . Notice the negative sign inside the function! - If your prediction is correct (
is a positive number, say ), the formula becomes . The maximum of and is . So, there is zero penalty for being correct. - If your prediction is wrong (
is a negative number, say ), the negative sign flips it: . The maximum is . The loss is . - Therefore, the loss is never negative. It is exactly
for correct predictions, and it scales up linearly (like a ramp) the further wrong a prediction is.
- If your prediction is correct (
Because it forms a continuous ramp instead of a sharp cliff, the computer can now measure a slope and adjust the weights, making it a functional approximation of the Zero-One loss. However, while it is convex, it is not strictly convex (it doesn't form a perfect rounded bowl), which can sometimes make optimization slightly less smooth than other methods.
Square loss
The Math
(1) The square loss function is commonly used for regression problems.
(2) It can also be used for binary classification problems as
where
(3) Note that the square loss tends to penalize wrong predictions excessively. In addition, when the value of
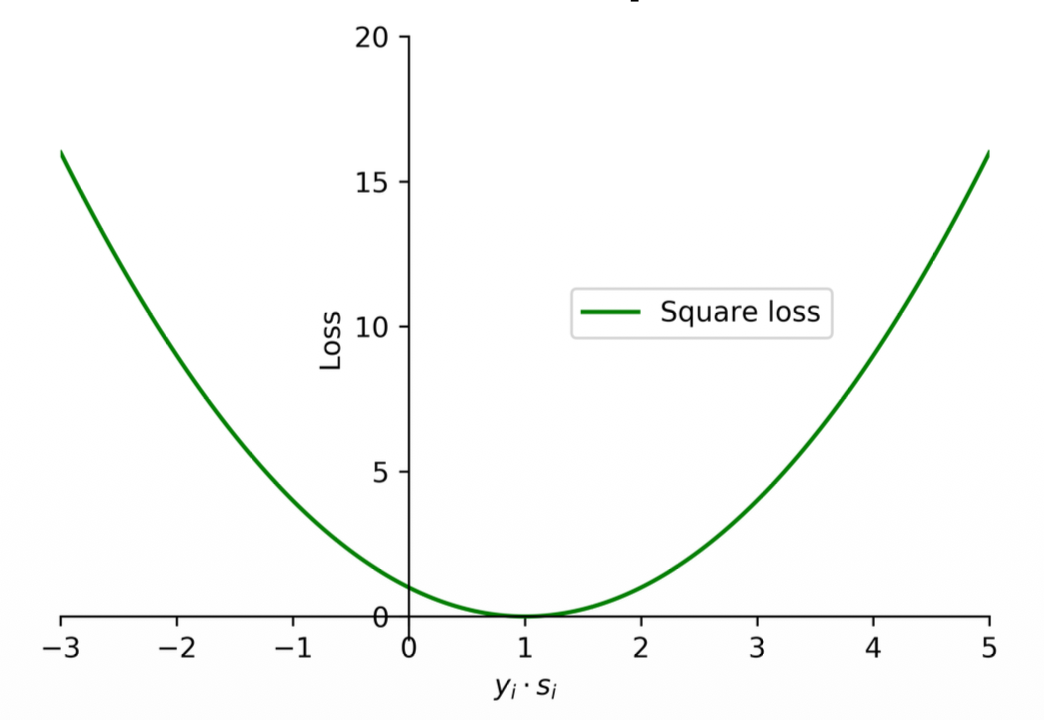
Notes:
- This will not perform well because whenever you have a correct prediction the loss will still be high!
The Meaning
Square Loss: The Danger of Being "Too Right" Next, the slide introduces the Square Loss:
- Fixing the note: "This will not perform well because whenever you have a correct prediction the loss will still be high!" This is close, but needs a slight correction. If
is exactly , the loss is . So it can be zero. The real problem is what happens when is very large (e.g., ). A large means the model's prediction is both correct and extremely confident. If we plug into the formula: .
This is the fatal flaw of using Square Loss for classification: it severely penalizes the model for being "too correct". Because it is a parabola (a U-shape), the penalty shoots up equally on both sides. The model will waste its time trying to pull its highly confident correct predictions back down to exactly
While Square Loss is perfectly smooth and strictly convex (making the math very easy), this over-penalization of correct predictions makes it a poor choice for classification tasks.
Log loss (cross entropy)
The Math
(1) Logistic regression employs the log loss (cross entropy) to train classifiers.
(2) The loss function used in logistic regression can be expressed as
where
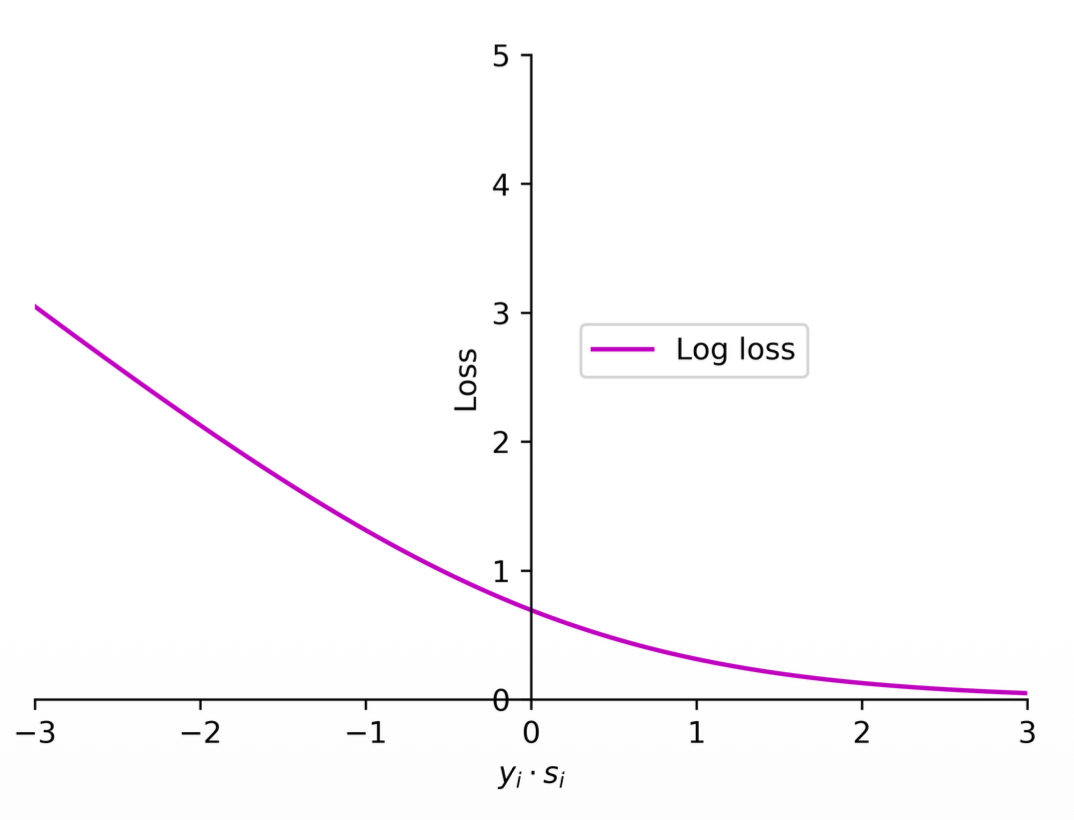
Notes:
- Note this is still some kind of approximation of the zero-one loss
- This is commonly used because it is a continuous function and differentiable everywhere
- What is the difference between Perceptron loss and cross entropy loss?
- Should there be some loss close to 0 or not?
- Yes, even though it is positive, it is small and represents a weak prediction even though it is correct, we can measure this with the Log loss by applying some loss closer to the 0 boundary
- The Log loss basically makes it so that the bigger the number (positive) the less the loss.
- The cross entropy loss is differentiable!
- For logistic regression there is no perfect sample, every sample has some loss
- For strong predictions this value would be very small but never will be zero
- This is because of how logs work (horizontal asymptote at 0)
- Should there be some loss close to 0 or not?
The Meaning
1. Log Loss (Cross Entropy) is perfectly smooth and everywhere differentiable. It forms a perfect, rounded bowl (it is strictly convex), which is exactly why we love using it for Gradient Descent.
- It is the Perceptron Loss and the Hinge Loss that have a "sharp edge" (a non-differentiable point where the line suddenly hinges like a bent knee).
2. Log Loss: Never satisfied, always pushing You asked in your notes: "Should there be some loss close to 0 or not?" The answer is yes! If
- The Perceptron Loss stops caring the absolute millisecond the prediction is correct (
). It assigns penalty. - The Log Loss realizes that a weak prediction is dangerous. Because of the horizontal asymptote of the log function, the loss never truly reaches exactly zero. It continuously applies a tiny penalty to correct predictions, forcing the algorithm to push the weights to be as confident as possible.
Hinge loss (support vector machines)
The Math
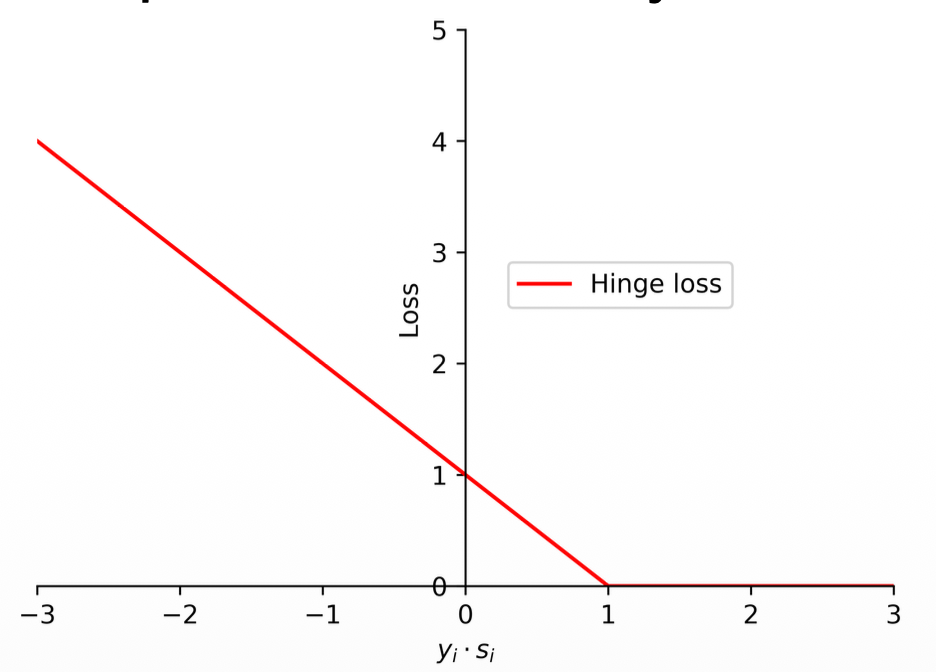
(1) The support vector machines employ hinge loss to obtain a classifier with "maximum-margin".
(2) The loss function in support vector machines is defined as follows:
where
(3) Different with the zero-one loss and perceptron loss, a data may be penalized even if it is predicted correctly.
Notes:
- Differences of the Hinge loss
- Note the difference from perceptron loss:
- Perceptron loss:
- Hinge loss:
- Perceptron loss:
- The only difference is that 1, and it has a significant impact
- Essentially it shifts the curve by 1.
- This applies some loss for the positive predictions closer to 0, like the log loss
- But still is not a differentiable function
- Note the log loss would still be a little bit more harsh on positive predictions closer to 0 (applies a bit more loss)
- The reason we use this is because it could be the case that fits better our data helping the maximum margin (the distance between the loss line and the data points)
- The reason it is called maximum margin is because of that small loss that applies to weak correct predictions
- Note the difference from perceptron loss:
- Support and non-support vectors:
- If a data point has zero loss, if you remove this data point, and re-train, the model will remain the same.
- These are called non-support vectors (points that if removed, the model will remain the same)
- The other data points are support vectors (incorrect predictions and closer to 0 correct predictions)
- Look for a visual example of support and non-support vectors
- To distinguish these two is not trivial, because you need to identify all the data points and how the maximum margin would change if removed
- If a data point has zero loss, if you remove this data point, and re-train, the model will remain the same.
- Something interesting:
- Why is it 1? Why shifting by 1? is there any difference if we put a 5 there? What would be the difference?
- If you make it 0 it will just care about if predictions are correct or not (just like perceptron)
- If you use any positive number the effect will be the same!
- Regardless of by how many you scale, the margin will remain the same
- You can use any number! It is just a scale.
- The only reason that this loss is not really used in deep learning is because it only works for two classes.
The Meaning
3. Hinge Loss: Demanding a "Margin" of Safety The Support Vector Machine (SVM) uses Hinge Loss: 1. This 1 has a massive impact.
- Instead of just asking to be barely correct (
), Hinge Loss demands a margin of safety. It penalizes the model until the confidence score is strictly greater than or equal to ( ). - If the model gets the answer right but the score is only
, Hinge Loss still applies a penalty of . It forces the model to push the data points away from the boundary until they are safely past the threshold.
4. Support vs. Non-Support Vectors Because Hinge Loss becomes exactly zero once
- Non-Support Vectors: Any data point that is correctly classified and safely outside the margin (
) has loss. If you completely delete these points from your training dataset and retrain the model, the decision boundary will not move a single inch. - Support Vectors: The model's boundary is entirely propped up (supported) by the points that are inside the margin, on the margin edge, or completely misclassified. These are the only points the algorithm cares about.
5. "Why is it 1? Can we use 5?" Your intuition here is incredibly sharp and correct! If you used
6. Why deep learning prefers Log Loss Your note suggests Hinge Loss isn't used in Deep Learning because it only works for two classes. While multi-class adaptations of Hinge Loss do exist, the real reason Deep Learning universally prefers Log Loss is back to your first note: Differentiability and Probabilities. Log loss is completely smooth (easy for backpropagation/gradient descent) and pairs perfectly with the Softmax function to output clean percentages (probabilities), whereas Hinge Loss just outputs raw, hard boundary scores.
Exponential Loss
The Math
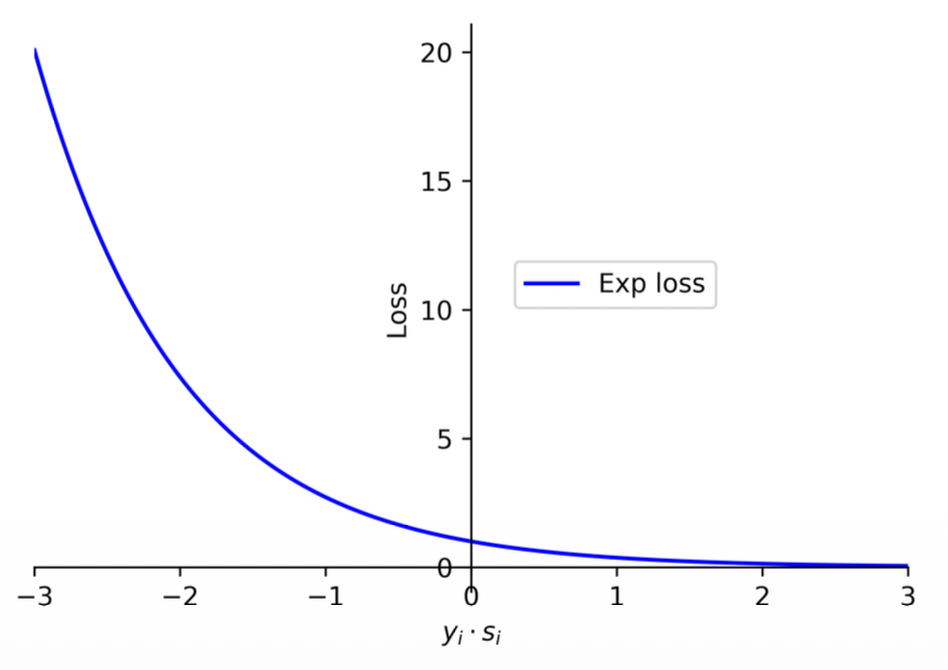
(1) The log term in the log loss encourages the loss to grow slowly for negative values, making it less sensitive to wrong predictions.
(2) There is a more aggressive loss function, known as the exponential loss, which grows exponentially for negative values and is thus very sensitive to wrong predictions. The AdaBoost algorithm employs the exponential loss to train the models.
(3) The exponential loss function can be expressed as
Notes:
- Some commercial models and libraries use this loss
- It penalizes data points that are wrong and be a little bit more permissive in correct predictions closer to 0.
The Meaning
Exponential Loss: The "Aggressive" Metric The formula for Exponential Loss is
- Perceptron Loss:
. - Log Loss:
. - Exponential Loss:
.
As you can see, Exponential Loss punishes wrong predictions astronomically! If even a single data point is misclassified by a large margin, the error skyrockets. This forces the learning algorithm to focus intensely on fixing its biggest mistakes. This is the exact mathematical engine that powers AdaBoost (a famous algorithm that builds classifiers by obsessively focusing on the hardest-to-classify data points).
- Note on your notes: "a little bit more permissive in correct predictions closer to 0". Actually, its main defining trait is how extremely un-permissive it is to negative numbers (wrong predictions). For correct predictions, it smoothly decays to
as confidence grows, much like log loss.
Convexity
The Math
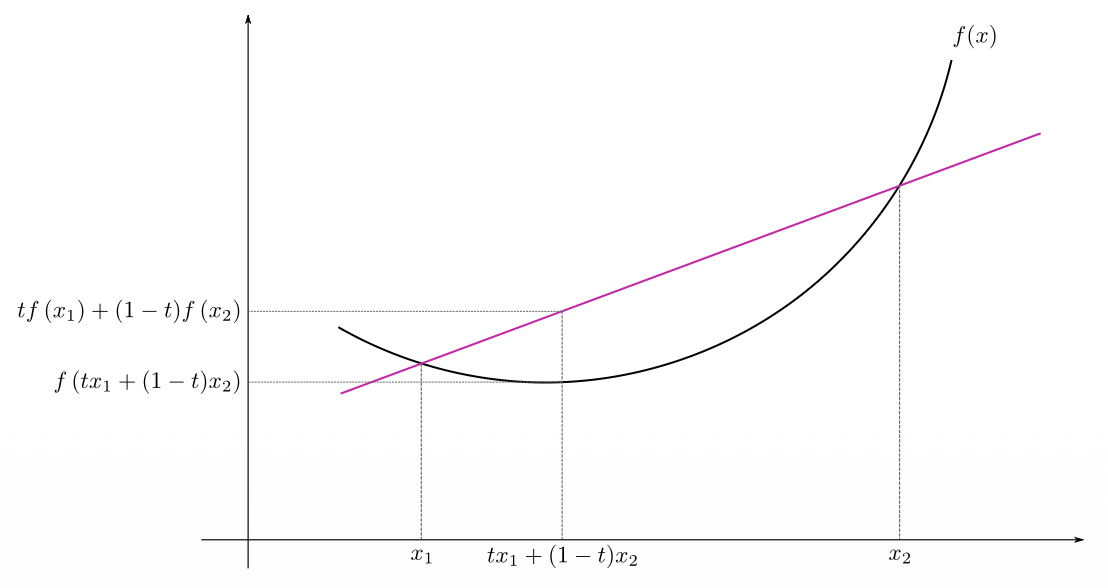
(1) Mathematically, a function
(2) A function
(3) Intuitively, a function is convex if the line segment between any two points on the function is not below the function.
(4) A function is strictly convex if the line segment between any two distinct points on the function is strictly above the function, except for the two points on the function itself.
(5) In the zero-one loss, if a data sample is predicted correctly
(6) For the perceptron loss, the penalty for each wrong prediction is proportional to the extent of violation. For other losses, a data sample can still incur penalty even if it is classified correctly.
(7) The log loss is similar to the hinge loss but it is a smooth function which can be optimized with the gradient descent method.
(8) While log loss grows slowly for negative values, exponential loss and square loss are more aggressive.
(9) Note that, in all of these loss functions, square loss will penalize correct predictions severely when the value of
(10) In addition, zero-one loss is not convex while the other loss functions are convex. Note that the hinge loss and perceptron loss are not strictly convex.
Notes:
- Convex functions look like that
- If you plot a straight line you can touch two points of the curve
- Convex:
- the line segment between any two points on the function is not below the function
- Strictly convex:
- the line segment between any two distinct points on the function is strictly above the function (except for the two points on the function itself)
The Meaning
1. Convexity: The Mathematics of a "Bowl" You already know intuitively that a convex function looks like a bowl, which is great for Gradient Descent. The slide provides the formal mathematical proof of what a "bowl" is: $$f(t x_1 + (1-t) x_2) \leq t f(x_1) + (1-t) f(x_2)$$ Let's translate this math into English:
- Imagine picking two points on the curve,
and . - The term
just means "choose an -coordinate somewhere exactly between and ." - The left side of the equation (
) is the actual curve of the function at that middle point. - The right side of the equation is a straight line drawn between the two points.
- The formula simply says: "The curve must always dip below (or equal) the straight line." If you draw a line across the top of a bowl, the bottom of the bowl is always beneath the line!
2. Convex vs. Strictly Convex Why do we care about "Strictly" convex?
- Convex (
): The curve can dip below the line, or it can be perfectly flat and equal the line. The Perceptron Loss and Hinge Loss are V-shaped or have flat sections. They are convex, meaning a rolling ball won't get trapped in a fake local minimum, but because of the flat parts, the ball might stop rolling on a flat "plateau" (a valley floor) instead of a single perfect point. - Strictly Convex (
): The curve strictly dips below the line. There are absolutely no flat parts. Square Loss, Log Loss, and Exponential Loss are strictly convex. This guarantees there is exactly one unique, perfect global minimum at the very bottom of a rounded bowl.
Summary
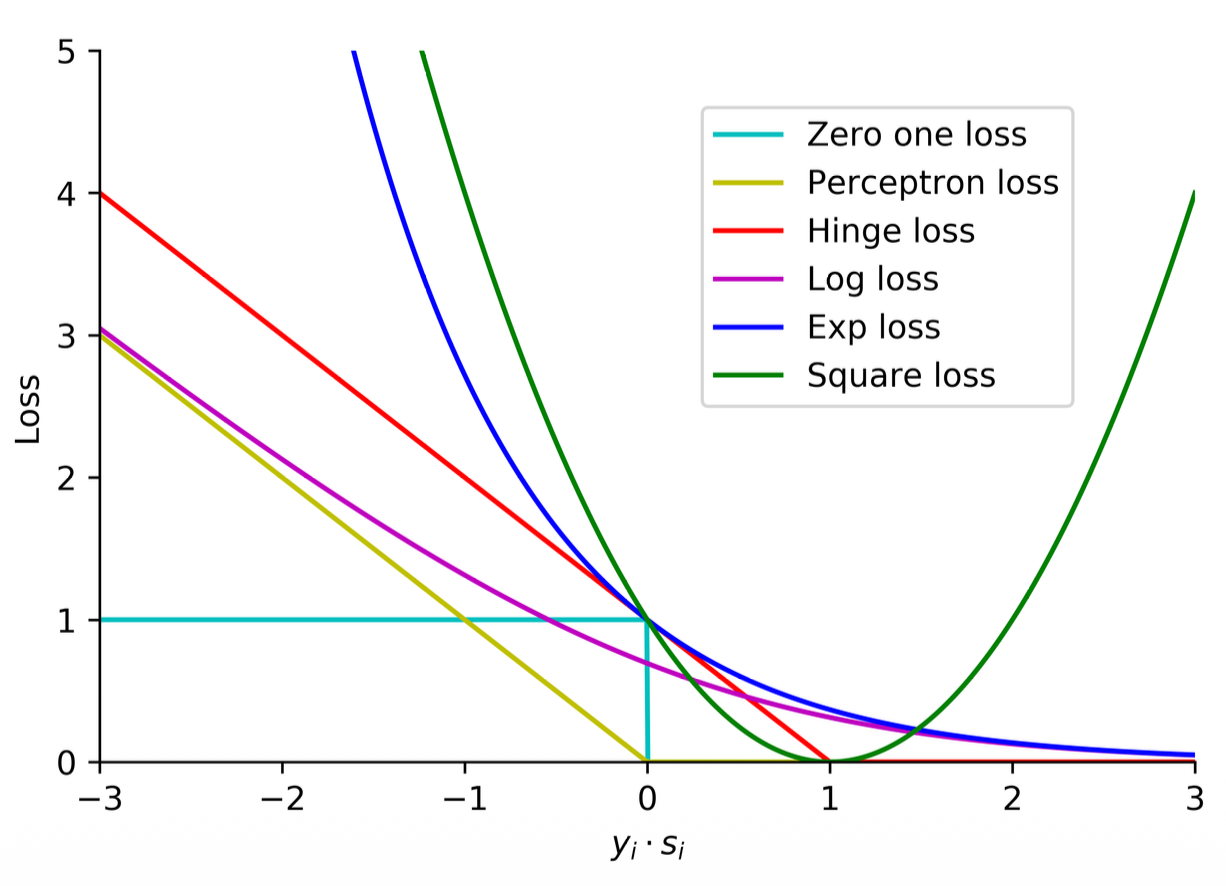
-
The key difference is from 0 to 1 and what happens if they are too close to the boundary.
-
All of these are continuous except for the zero-one loss
-
The log loss is especially differentiable at any point so that is why this is the one we use the most
-
Convexity:
- Zero-one: not convex
- Perceptron: is convex but not strictly convex
- Square loss: both convex and strictly convex
- Log loss: both convex and strictly convex
-
Continuous, differentiable and strictly convex functions are easier to optimize, this is why we use the log loss!
- 90% of the time you will use Log loss
- 9% of time you use Hinge loss
- 1% the rest of the function (very specific cases)
The Grand Summary of Loss Functions The end of your slide brilliantly summarizes everything you need to know for choosing a loss function:
- Zero-One Loss: Perfect in theory (counts exact errors), but impossible to optimize because it is a flat stair-step (not convex, not differentiable).
- Square Loss: Perfectly smooth and strictly convex, but terrible for classification because it severely penalizes the model for being "too correct" (
). - Perceptron & Hinge Loss: Convex, but not strictly convex (they have sharp corners/flat edges). Good for finding margins, but you can't always use simple Gradient Descent easily on the sharp corners.
- Log Loss: The Goldilocks function. It is continuous, everywhere differentiable, and strictly convex. It smoothly pushes correct predictions to be more confident. This is why it is the absolute standard for Logistic Regression and Deep Learning.
- Exponential Loss: Also smooth and strictly convex, but highly aggressive. It is used specifically when you want an algorithm (like AdaBoost) to fiercely penalize errors.