10 - Attention, Transformers, and Large Language Models
Class: CSCE-421
Notes:
These slides are based on Chapter 12 of Deep Learning: Foundations and Concepts
Example
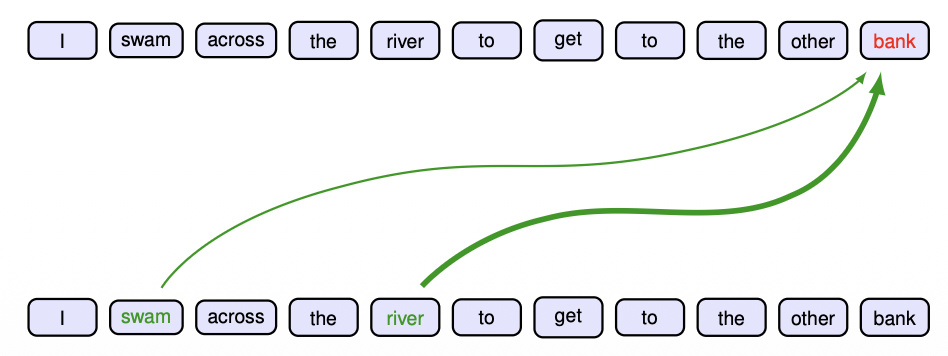
I swam across the river to get to the other bank.
I walked across the road to get cash from the bank.
- Appropriate interpretation of 'bank' relies on other words from the rest of the sequence
- The particular locations that should receive more attention depend on the input sequence itself
- In a standard neural network, the weights are fixed once the network is trained
- Attention uses weights whose values depend on the specific input data
Notes:
- How do we deal with sentences-words?
- The meaning of a word sometimes depends on the context, this is the key idea that LLMs work around.
- Image you have a sentence like the above
- I will somehow process and match each of these words into a vector
- The vector needs to be of the same dimension of course
- Then you will have a sequence of vectors, with each vector representing a word, then you will produce a sequence of vectors as outputs, and you will do this in many layers.
- The key operation is that you have a sequence of words, equivalent to a sequence of vectors and you can transform this into a sequence of vectors as output.
- I will somehow process and match each of these words into a vector
- We want to transform from the input vectors to the output vectors
- The number of words in this unit cannot change!
- If you have 10 vectors as input, your output will be 10 vectors
- Across different layers, the number of layers can change but the number of vectors cannot.
- The key idea here is: if the input vectors are given, how do we get the output vectors?
- If you want this vectors to capture semantics, what do we need to do?
- The vector for a specific word has to deppend in many input vectors
- To compute each of these output vectors will depend on all of the input vectors
- Each of the output vectors will be a linear combination of the input vectors
- Which one is more important? we do not worry about that, that is learnt in training.
- This is the idea of Attention: pay different attention to different inputs with different weights
- First how can we convert a word into a vector?
- The first layer needs to convert each of the words into a vector
- This layer is called the embedding layer
- There is a very simple way: one-hot representation
- Lets say there are 50,000 words in English, now you have a vocabulary, each word has an index in that vocabulary (a fixed number in that vocabulary), then you can convert each of this words into a vector of 50,000 thousand dimensions, with the single index entry corresponding to the word is 1, and all the other entries are 0.
- Note each vector will correspond to a word, and therefore the number of vectors cannot change
- But your network needs to be able to take different input sizes
- Most discussions: given a sequence of vectors, how do you produce another sequence of vectors. This is also called Attention
Neural language and word embedding
- Convert the words into a numerical representation that is suitable for use as the input to a deep neural network
- Define a fixed dictionary of words and then introduce vectors of length equal to the size of the dictionary along with a 'one hot' representation for each word
- The embedding process can be defined by a matrix E of size
where is the dimensionality of the embedding space and is the dimensionality of the dictionary. - For each one-hot encoded input vector
we can then calculate the corresponding embedding vector using
- Word embeddings can be viewed as the first layer in a deep neural network. They can be fixed using some standard pre-trained embedding matrix, or they can be trained
- The embedding layer can be initialized either using random weight values or using a standard embedding matrix
Notes:
- Understand the equation:
is a one-hot representation vector of the word. (Each of these words are a one-hot vector) The dimension of this vector is the number of words in the vocabulary. - One location that has a value of 1, and every other location has a value of 0.
- You can use it but this might not be a good representation, just because it is a extremely long vector containing all 0s but a 1.
- What you do is multiply the matrix
( ). - Remember matrix multiplication is a linear combination of columns
- By far the most important operation in linear algebra matrix-vector multiplication
- You multiply each element on the vector to each of the columns and sum them together.
- You basically take a particular column of this matrix because all entries on
are 0, except for the word entry. - You are basically converting a long vector into a shorter vector
is learned, and is called the embedding matrix.
- The output will be
, it is the vector that we used as the input to the next layer for process. - This is nothing but a fully connected network thanks to a matrix multiplication, we are applying a fully connected network to every location of the input (every word vector) - one applied for each word separately.
- A little bit more context:
- Imagine you have the previous sequence of words. Intuitively your first step is to convert each word into its one-hot English representation.
- You will then have
- Then your output vectors would look like:
- You will then have
- The operation in between is matrix-multiply with
. - But what is this operation in terms of neural networks? (use neural network terminology - not mathematically)
- It is forward propagation? yes
- We are talking about a fully connected layer? yes, but there is something else...
- This is nothing but a neural network layer that you already know
- But what else is
? - You have one fully connected layer that is shared across all the words, it is a single
. - A fully connected network
- The key is that the same network is applied to each of the input vectors.
- This is simply a fully connected layer but shared among all the input vectors.
- You have one fully connected layer that is shared across all the words, it is a single
- But what is this operation in terms of neural networks? (use neural network terminology - not mathematically)
- Imagine you have the previous sequence of words. Intuitively your first step is to convert each word into its one-hot English representation.
- Exam question: Explain the embedding layer from a neural network point of view.
- -> fully connected layer shared among all the input vectors
- But this is just the first layer!
Transformer processing
The input data to a transformer is a set of vectors
- Combine the data vectors into a matrix X of dimensions
in which the th row comprises the token vector , and where labels the rows - A Transformer takes a data matrix as input and creates a transformed matrix
of the same dimensionality as the output - We can write this function in the form
/CSCE-421/Ex2/Visual%20Aids/image-27.png)
Notes:
- This is the data in a particular layer
- For now, think of each token as a word.
- If you have 5 words, you will have 5 vectors in the matrix X
- We need to be able to take this X matrix and transform it into
- Inside this layer the vectors have to be the same dimensions, otherwise we can not put this into a matrix.
- So now the question is given a matrix, how can we produce a new matrix.
Attention coefficients
- Map input tokens
to - The value of
should depend on all the vectors - Dependence should be stronger for important inputs
- Define each output vector
to be a linear combination of :
where
Commonly used coefficients
We have a different set of coefficients for each output vector
Notes:
- input sequence: x1,...,xn (each of these is a vector)
- the number of vectors cannot change
- output sequence: y1,...,yn
- each of these outputs depend on all the input vectors
- (will be a linear combination of each of the input vectors)
- More important ones will be given a larger weight, less important ones are given a smaller weight.
- Note
is just in linear combination with for a particular - This is a coefficient, and summing all of them will give 1.
- The whole idea here is that through this entire network the number of vectors will not change.
- Attention is basically is how to get
- We are trying to compute
because if we can do this for one vector, we can do it for all of them - All we need is
where
- All we need is
- Lets say we are computing this coefficient, how?
- You will take your
and take its product with each of the - The output will sum to 1, and every coefficient will be between 0 and 1.
- You will take your
- We are trying to compute
Attention in general (cross attention) - IMPORTANT
- Use of query, key, and value vectors as rows of matrices Q,K,V
/CSCE-421/Ex2/Visual%20Aids/image-28.png)
Notes:
- We are defining a more general attention operation, for this we introduce the general Q, K, V.
- Attention: In the most general case, the attention operation will take 3 sequences of vectors as inputs and produce 1 sequence of vectors as output.
- Q (sequence of vectors)
- K (sequence of vectors)
- V (sequence of vectors)
- Self attention:
- Where Q = K = V = X (generally)
- You can always give Q, K, V the same things, but you are better giving something more useful
- The question is: How to produce one vector in the output.
- You take an arbitrary row in Q, and produce a sequence of vectors for that row.
- We will take the pink vector in Q, then do an inner product of this vector and each rows of K,
- Then this vector is passed through Softmax to get another vector (converting to
[0,1]and sum to 1).- It turns out if you give Q, K, V the same x, this will be just 1.
- Then you again do an inner product of this vector with all rows on V to get the final one vector sequence.
- Question: The sizes of Q, K, V cannot be arbitrary, otherwise these operations won't work. But in general they do not have to be exactly the same size, but there has to be some kind of constraint for this to work.
- The inner product is matrix multiplication of K^T so we need the same number of columns on Q and K.
- Not necessarily same number of rows because we are either way takin each row on Q and inner product it with each row on K. They do not necessarily need to match.
- Size of the cross vector will equal to the number of rows in K.
- Softmax will not change the size.
- K and V need to have the same number of rows, in order for each number to have a cross product.
- The inner product is matrix multiplication of K^T so we need the same number of columns on Q and K.
- Question: How about the size of this output vector sequence?
- We want to know how the size of the output relates to the size of the input
- We will put this sequence of vectors into a matrix.
- We want to know how many vectors are produced, and what is the size of each vector
- The number of columns of each vector in this sequence needs to be the same as the number of columns in V.
- Dimensions haves to equal in order to do the cross product
- Now how many vectors?
- The number of rows in Q?
- We want to know how the size of the output relates to the size of the input
- Question: If we permute rows in certain way, how the output will be changed?
- Rows will also be permuted, because each row will be computed separately.
- Moving a row in Q will just move the row in the output sequence.
- What kind of property is this?
- If you swap certain row, is equivalent to swapping certain words!
- This is called permutation equivariance
- It has a very important consequence in language models
- If you change the order of the inputs, it will change the order of the outputs.
- In natural languages this is not desired, because different order of words mean different things, so we need to do something else?
- An answer will just be a permuted version of a prompt, which is not what we want.
- Question: What happens if we permute the rows in K and V (they have the same number of rows) using the same permutation, how the output would be changed?
- It won't change!
- It would only change if we permute one of them without permuting the other one.
- This is because we use the a vector of Q to compute each of the cross products for each vector in K, since we have the same order in V because we also permuted it as K, then everything will remain the same.
- Note the most common case of this setup is for each of these Q, K, V to be the same matrix
- This is called the self potential.
- If my X is permuted, all of the Q, K, V will be permuted the same way
- This means that the output will change because of Q being permuted
- But the output remains in that way (after being permuted by Q) when applying K and V (those do not change the output).
- There is still a little bit something we need to do before, but for now this is the model
- Do you think this will work in LLMs as of right now? NO
- We haven't learned anything, we cannot train yet!
- But there is a small step to make it work, we need to introduce some learning parameter.
- Do you think this will work in LLMs as of right now? NO
- We can put all of this operations into a Matrix Form!
General attention in matrix form
- The attention computes
where Softmax
- Whereas standard networks multiply activations by fixed weights, here the activations are multiplied by the data-dependent attention coefficients
/CSCE-421/Ex2/Visual%20Aids/image-30.png)
Notes:
- This is by far the most common Attention equation. It is a key operation you need to know for Language Models
- We take one row in the Q matrix and compute the inner product with each of the columns in K, this is represented by
. - Q is a row vector and K is a column vector
- Inner product between one row in Q and all rows in K
- After softmax of this you still have a row vector of the same size.
- Then you multiply with matrix V, which is the same as doing the linera combination of each row
- People sometimes call this cross-attention
Self-attention without parameters
- We can use data matrix
as , along with the output matrix , whose rows are given by , so that
where Softmax
- This process is called self-attention because we are using the same sequence to determine the queries, keys, and values
- The transformation is fixed and has no capacity to learn
Notes:
- This is a special case where KQV is XXX (all of them are the same X matrix)
- This is called slef-attention
- But we need to somehow introduce some learnable parameters in the network
Self-attention with parameters
- Define
governs the dimensionality of the output vectors - Setting
will facilitate the inclusion of residual connections
/CSCE-421/Ex2/Visual%20Aids/image-31.png)
Notes:
- Note the right part is just the general attention operation
- Note you only have one X matrix
- What we will do is that for X to Q you multiply X with that matrix, and the results will be Q
- For K you multiply X with another matrix W
- Similarly you get V by multiplying X by a matrix W
- These three W matrices are different ad completely independent, and these are the parameters of the network.
- In this case you do not need to worry about dimension, it will automatically match.
- The size of QKV will depend on the sizes of your W matrices
- What do we need to do to setup this constraint on the network so that we have matching sizes?
- We need to ensure the number of columns between these two matrices are the same
- When you multiply two matrices AB, you need to make sure the number of columns on A, needs to be the same as the number of rows on B
- For example A (m * n) B (n * p) = C (m * p)
- So we have to match number of columns! That is correct but still is too restrictive, we can go finer than this!
- Do we need to worry about the same number of rows?
- No, we do not need to worry, we do not have a choice
- Otherwise the dimensions will not match
- For example A (m * n) B (n * p) = C (m * p)
- The only thing you need to worry about in this case is that the number of columns of Q and K matrices have to be the same.
- Note the dimension (k) refers to the same number of (k) columns
Comparison of Cross and Self Attention
/CSCE-421/Ex2/Visual%20Aids/image-32.png)
Notes:
- Note on self-attention you have only one matrix as input, your X matrix
- You multiply this matrix with the 3 W matrices, once you do that, you get QKV
- Then you follow the path of the general attention operation
- In cross attention you have more than one input matrix
- The only thing you need to worry about here is that the attention operation will be exactly the same, and the output is a single matrix but here you have multiple input matrices
- You use X1 to derive Q and V
- You use X2 only to derive K
- So attention itself is identical but number of inputs can change
- Remember so far we are just taking a sequence of vectors and producing another sequence of vectors, that is attention
- Later you will see how this evolves in encoder/decoder architectures, but sometimes this is the only thing we need
Dot-product scaled attention
- Let
denotes the -th element of , we have : small for inputs of high magnitude - If the elements of the query and key vectors were all independent random numbers with zero mean and unit variance, then the variance of the dot product would be
- Normalize using the standard deviation
/CSCE-421/Ex2/Visual%20Aids/image-33.png)
Notes:
- The attention we have talked about so far is: softmax(QK^T)V
is the number of columns in Q and K: You can set it to be a very small or large number - Depending on how this learns, values in the inner product could be very large, sometimes a small number of a large number, therefore we need to normalize this.
- This equation is by far the most final attention equation -> scaled.
Multi-head attention
- Suppose we have
heads indexed by as
- Define separate query, key, and value matrices for each head using
- The heads are first concatenated into a single matrix, and the result is then linearly transformed using a matrix
as
- Typically
is chosen to be equal to so that the resulting concatenated matrix has dimension
/CSCE-421/Ex2/Visual%20Aids/image-34.png)
- Y is exactly the same size of x because we want to use a residual connection
Notes:
- How this works is like this:
- You have the attention operation, the output is
- Here we only have on set of input, and by default we talk about self-attention
- Input is X
represents height
- You need to apply self attention multiple times
- Since you only have one X, you use completely 3 different matrices (
) and multiply them one by one by the X matrix.
- Since you only have one X, you use completely 3 different matrices (
- We have multiple outputs now, how do we deal with the output matrix? (we applied
three times) is a matrix, you somehow put the result together in a meaningful way, lets say you concatenate them, how do you do that? - There is only one way you can do this
- Out constraint is that we have a sequence of vectors as input and a sequence of vectors as output, and the output number of vectors cannot chaange, because each word represents one vector.
- The onyly way to do this correctly is to concatenate them is to do:
- This is because the number of rows (number of vectors) cannot change
- This may reduce or change the number of columns, but the number of rows remains the same
- The output will be multiplied by another matrix
- This controls the number of columns we want
is the size of the X matrix, is the number of heads
- You have the attention operation, the output is
- Most time what we try to do is that we have attention just being a layer of our network, our next step is to build a block:
- attention layer
- normalization layer
- skip connection
- So what we want to do is that we want to still have a skip connection
- In order to do that, is that if our attention in this block is multi-head (did it 3 times) each time we will produce a matrix with the same number of rows and some number of columns
- What we will produce is
- This whole thing together has the same dimension as our input
- At the end we need to make sure these two maps produce matrices or feature maps of the same size
Question: Why are we doing this multi-head attention?
- Lets say we use two heads, therefore we have 6 matrices, for Q we have two matrices W1(q) and W2(q)
- Two ways to do attention with 2 heads:
- Traditional:
- Do attention twice and have 6 different
matrices
- Do attention twice and have 6 different
- More columns:
- Make
- Now wea re doing attention once but with an extended Q with more columns
- Will this produce the same result?
- The only reason these are different is the softmax
- If you reduce the softmax operation from the traditional way you get the same thing!
- The reason: all of this operations are linear, you just make everything longer
- Make
- Traditional:
- Therefore using
, ... is equivalent to
The most common version of attention is the dot product scaled multi-head self attention.
Transformer layers
- Stack multiple self-attention layers on top of each other
- Introduce residual connections and require the output dimensionality to be the same as the input dimensionality, namely
- Followed by layer normalization to improves training efficiency
- Sometimes the normalization layer is applied before the multi-head self-attention as
/CSCE-421/Ex2/Visual%20Aids/image-35.png)
Notes:
- This is essentially a layer (just like a convolutional layer)
- Our input is scaled x (sequence of vectors), and again we will have a sequence of vectors y with the same size (same number of rows)
- We apply multi-head self-attention (the most commonly used)
- Why are we doing LayerNorm?
- Think of images, when we train convolutional networks we have this idea of mini-batches, you give some number of images as input
- When we train language models, we train them with multiple sentences
- Each time you give multiple sentences
- You cannot do batch norm because each sentence may have different length, the number of words may not match
- LayerNorm is to normalize each sample by itself (not across different sentences that may have different length)
- After multi-head attention you will add X to it, then you do layer normalization, this will give you Z.
- In practice people have found out that layer normalization can be applied to the given X, and after apply attention
- This is called pre-norm attention -> normalization moved forward one step
- Eventually your network is a set of many layers, it is just a matter where to apply normalization, and people find out that applying normalization before attention has worked better
- But so far we have only talked about how to get Z
MLP in Transformer layers
- The output vectors are constrained to lie in the subspace spanned by the input vectors and this limits the expressive capabilities of the attention layer
- Enhance the flexibility using a standard nonlinear neural network with
inputs and outputs - For example, this might consist of a two-layer fully connected network with ReLU hidden units
- This needs to preserve the ability of the transformer to process sequences of variable length
- The same shared network is applied to each of the output vectors, corresponding to the rows of Z
- This neural network layer can be improved by using a residual connection and layer normalization
Transformer layers
- The final output from the transformer layer has the form
- Again, we can use a pre-norm as
- In a typical transformer there are multiple such layers stacked on top of each other
Notes:
- In transformers there is another block called MLP
- This is the Multi-Layer Perceptron (A multi-layer network)
- Again we might use pre-norm, it is similar to the previous block were we used it before applying attention
- But the question is how is MLP applied?
- All we have in Z is a sequence of vectors, how do we apply an MLP of that matrix?
- We treat rows of Z as vectors
- We need to make sure our network can process vectors of any length because the number of words might be different for each row
- Basically we need to apply a single MLP into each of the vectors in Z
- (we have the same multi-layer network applied to each vector on the sequence Z)
- So we apply MLP per row!
- You can see transformers by themselves is just sequence of vectors as input -> sequence of vectors as output of the same size!
- Just by using this in slightly different way we can build different language models but this is the fundamental model!
Positional encoding
- The transformer has the property that permuting the order of the input tokens, i.e., the rows of
, results in the same permutation of the rows of the output matrix - equivariance - The lack of dependence on token order becomes a major limitation when we consider sequential data, such as the words in a natural language
- 'The food was bad, not good at all.'
- 'The food was good, not bad at all.'
- Construct a position encoding vector
associated with each input position and then combine this with the associated input token embedding - An ideal positional encoding should provide a unique representation for each position, it should be bounded, it should generalize to longer sequences, and it should have a consistent way to express the number of steps between any two input vectors irrespective of their absolute position because the relative position of tokens is often more important than the absolute position
Language models: Narrow sense
- Language models learn the joint distribution
of an ordered sequence of vectors, such as words (or tokens) in a natural language - We can decompose the distribution into a product of conditional distributions in the form
- We could represent each term by a table whose entries are estimated using simple frequency counts
- However, the size of these tables grows exponentially with the length of the sequence
Notes:
- This is the second equation you need to know apart from attention with normalization
- The key here is like this:
- Language Models can only do one thing: learn the joint distribution p(x1, ..., xN), it basically just tells you a number
- The probability tells you how likely this sequence is valued the same?
- This is essentially the product rule of probability
- You only need to know two rules of probability: sum rule and product rule
- This tells us:
- And:
n-gram model and LLMs (Courtesy R. Kambhampati)
- Language models learn the joint distribution
of an ordered sequence of vectors, such as words (or tokens) in a natural language - We can decompose the distribution into a product of conditional distributions in the form
- We could represent each term by a table whose entries are estimated using simple frequency counts
- However, the size of these tables grows exponentially with the length of the sequence
Language models: Broad sense
- Encoder only: In sentiment analysis, we take a sequence of words as input and provide a single variable representing the sentiment of the text. Here a transformer is acting as an 'encoder' of the sequence
- Decoder only: Take a single vector as input and generate a word sequence as output, for example if we wish to generate a text caption given an input image. In such cases the transformer functions as a 'decoder', generating a sequence as output
- Encoder-Decoder: In sequence-to-sequence processing tasks, both the input and the output comprise a sequence of words, for example if our goal is to translate from one language to another. In this case, transformers are used in both encoder and decoder roles