Weak Brute-Force Protection
After understanding different brute-force attacks on authentication mechanisms, this section will discuss security mechanisms that thwart brute-forcing and how to potentially bypass them. Among the common types of brute-force protection mechanisms are rate limits and CAPTCHAs.
Rate Limits
Rate limiting is a crucial technique employed in software development and network management to control the rate of incoming requests to a system or API. Its primary purpose is to prevent servers from being overwhelmed by excessive requests, prevent system downtime, and protect against brute-force attacks. By limiting the number of requests allowed within a specified time frame, rate limiting helps maintain stability and ensures fair usage of resources for all users. It safeguards against abuse, such as denial-of-service (DoS) attacks or excessive usage by individual clients, by enforcing a maximum threshold on the frequency of requests.
When an attacker conducts a brute-force attack and hits the rate limit, the attack will be thwarted. A rate limit typically increments the response time iteratively until a brute-force attack becomes infeasible or blocks the attacker from accessing the service for a specified time period.
A rate limit should only be enforced on an attacker, not regular users, to prevent DoS scenarios. Many rate limit implementations rely on the IP address to identify the attacker. However, in a real-world scenario, obtaining the attacker's IP address might not always be as simple as it seems. For instance, if there are middleboxes such as reverse proxies, load balancers, or web caches, a request's source IP address will belong to the middlebox, not the attacker. Thus, some rate limits rely on HTTP headers such as X-Forwarded-For to obtain the actual source IP address.
However, this presents an issue, as an attacker can set arbitrary HTTP headers in a request, thereby bypassing the rate limit entirely. This enables an attacker to conduct a brute-force attack by randomizing the X-Forwarded-For header in each HTTP request, thereby avoiding the rate limit. Vulnerabilities like this occur frequently in the real world, for instance, as reported in CVE-2020-35590.
CAPTCHAs
A Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA) is a security measure to prevent bots from submitting requests. By forcing humans to make requests instead of bots or scripts, brute-force attacks become a manual task, making them infeasible in most cases. CAPTCHAs typically present challenges that are easy for humans to solve but difficult for bots, such as identifying distorted text, selecting particular objects from images, or solving simple puzzles. By requiring users to complete these challenges before accessing certain features or submitting forms, CAPTCHAs help prevent automated scripts from performing actions that could be harmful, such as spamming forums, creating fake accounts, or launching brute-force attacks on login pages. While CAPTCHAs serve an essential purpose in deterring automated abuse, they can also present usability challenges for some users, particularly those with visual impairments or specific cognitive disabilities.
From a security perspective, it is essential not to reveal a CAPTCHA's solution in the response, as we can see in the following flawed CAPTCHA implementation:
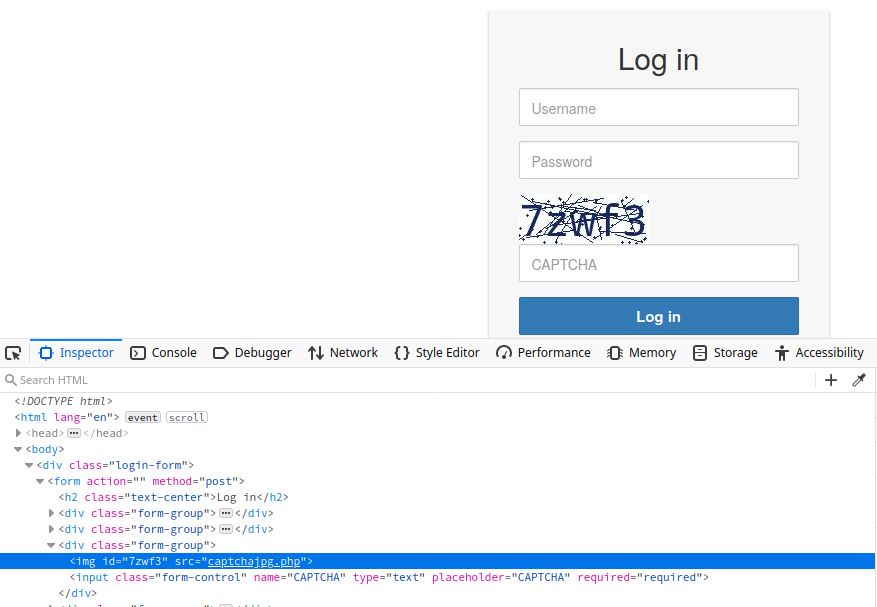
Additionally, tools and browser extensions that solve CAPTCHAs automatically are on the rise. Many open-source CAPTCHA solvers are available. In particular, the rise of AI-driven tools provides CAPTCHA-solving capabilities by utilizing powerful image recognition or voice recognition machine learning models.